Git 学习笔记
之前的笔记简单整理一下,方便刚接触的同学们快速入门
基本概念
对于一个程序员来说,Git可以说是一个必须掌握的基本技能。那么Git是什么呢,为什么对我们有这么大的作用?
Git是当下最流行,最好用的版本控制系统。所谓版本控制系统主要就是为了控制,协调各个版本的一致性。它增大了开发的灵活性,当遇到开发问题时可以随时回溯到上一个版本。Git属于分布式版本控制系统,也就是说每一个你clone下来的Git仓库都是主仓库的一个分布式版本。
因为clone下的数据都在本地,所以不仅提高了开发效率,而且即使我们离开了网络也可以执行提交,创建分支,查看历史版本记录等操作。
最后再来了解一个概念,Git本地有3个主要的工作区域
- 工作目录
- 暂存区域
- 本地仓库
具体作用我们在后面的基本操作中介绍
GitHub
GitHub是一个面向开源及私有软件项目的托管平台,也是一个全球最大的同性交友平台(???)你可以在上面学习到许多大佬的开源项目,同时也可以用于自己的项目开源与团队开发协作。
基本操作
首先注册GitHub 不多说了
初次配置
跟Github注册信息一致
$ git config --global user.name "yourname"
$ git config --global user.email "yours@example.com"
查看是否添加成功
git config --list
SSH key配置
推送是需要登陆输入GitHub用户名密码的,使用SSH公钥省可以省去这个环节。
1.创建SSH Key
首先在用户主目录下,看看有没有.ssh目录,如果有,再看看这个目录下有没有id_rsa和id_rsa.pub这两个文件,如果有的话可以跳到下一步。
如果没有,在终端(Windows下打开Git Bash)执行
ssh-keygen -t rsa -C "yours@example.com"
然后一直回车就行
 

2.GitHub配置SSH Key
Account–>settings–>SSH and GPG keys–>[New SSH Key]
 

Title 可以不填,会自动生成
在下面的Key中填入新生成的文件id_rsa.pub内容
Add后就配置成功了
创建本地仓库
首先创建目录 进入目录
mkdir xxx
cd xxx
初始化
git init
当前目录会生成一个.git文件夹用于管理Git仓库。它是 Git 用来保存元数据和对象数据库的地方。该文件夹非常重要,每次clone镜像仓库的时候,实际拷贝的就是这个文件夹里面的数据。具体细节有兴趣的可以深入了解下。
GitHub创建仓库
GitHub New Repository[https://github.com/new]
具体初始化步骤创建成功后会有显示 如下图 不多解释了

文件的三种状态
在了解常用命令之前,我们需要把之前简单提及了一下的概念再稍做深入。
我们要知道对于任何一个文件,在 Git 内都只有三种状态:已提交(committed),已修改(modified)和已暂存(staged)。已提交表示该文件已经被安全地保存在本地数据库中了;已修改表示修改了某个文件,但还没有提交保存;已暂存表示把已修改的文件放在下次提交时要保存的清单中。
由此我们看到也就是最开始基本概念中提及到 Git 管理项目时,文件流转的三个工作区域:Git 的工作目录,暂存区域,以及本地仓库。
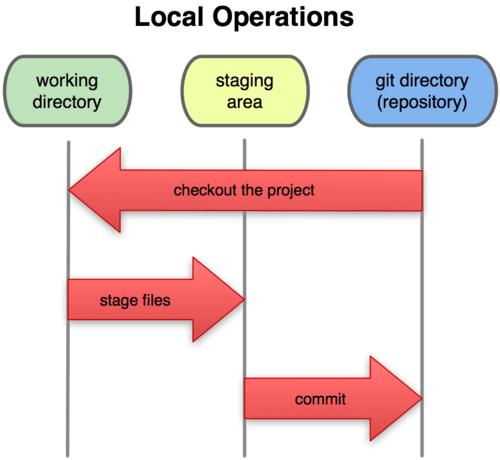 

我们可以从文件所处的位置来判断状态:如果是 Git 文件夹中保存着的特定版本文件,就属于已提交状态;如果作了修改并已放入暂存区域,就属于已暂存状态;如果自上次取出后,作了修改但还没有放到暂存区域,就是已修改状态。
常用命令
1.创建版本库
git clone <url> #克隆远程版本库
git init #初始化本地版本库
2.修改和提交
git status #查看状态
git diff #查看变更内容
git add . #添加所有改动过的文件
git add <file> #添加指定文件
git mv <old> <new> #文件改名
git rm <file> #删除文件
git rm --cached <file> #停止添加文件但不删除
git commit -m "commit message"#提交所有更新过的文件
git commit --amend #修改最后一次提交
3.查看提交历史
git log #查看提交历史
git log -p <file> #查看指定文件的提交历史
git blame <file> #以列表方式查看指定文件的提交历史
4.撤销
git reset --hard HEAD #撤销工作目录中所有未提交文件的修改内容
git checkout HEAD <file> #撤销指定的未提交文件的修改内容
git revert <commit> #撤销指定的提交
5.分支
git branch #显示所有本地分支
git checkout <branch/tag> #切换到指定分支或者标签
git branch <new-nbranch> #创建新分支
git branch -d <branch> #删除本分支
6.其他
git merge <branch> #合并指定分支到当前分支
git pull <remote> <branch> #更新代码
git push <remote> <branch> #上传代码
上面节选了常用的一部分网上Git速查表的内容,并不是全部。当然使用频率最高的是下面这几个,同时也是一般更新Git仓库的基本操作流程。
git clone <url>
git pull
(一系列修改代码/增加代码操作) #在工作目录处理文件
git add . #将文件添加至暂存区域
git commit -m "xxx" #将文件提交到本地仓库
git push
从项目中取出某个版本的所有文件和目录,用以开始后续工作的叫做工作目录。这些文件实际上都是从 Git 文件夹中的压缩对象数据库中提取出来的,接下来就可以在工作目录中对这些文件进行编辑。
所谓的暂存区域只不过是个简单的文件,一般都放在 Git 文件夹中。有时候人们会把这个文件叫做索引文件,不过标准说法还是叫暂存区域。
所以基本的操作如下:
- 在工作目录中修改某些文件。
- 对修改后的文件进行快照,然后保存到暂存区域。
- 提交更新,将保存在暂存区域的文件快照永久转储到 Git 文件夹中。
Git 工作流程
可以直接看这篇文章了,写的很好。Git 工作流程
使用建议:三个简单规则
 

- 规则一:为每个新项目创建一个Git存储库。
- 规则二:为每个新功能创建一个新分支。
- 规则三:用pull reqeust把代码合并到Master分支。
参考
https://medium.freecodecamp.org/follow-these-simple-rules-and-youll-become-a-git-and-github-master-e1045057468f
https://www.cnblogs.com/myqianlan/p/4195994.html
https://blog.csdn.net/xuda27/article/details/52617148
https://git-scm.com/book/zh/v2