根据StackTrace中Java行号定位jsp行号的方法
前言
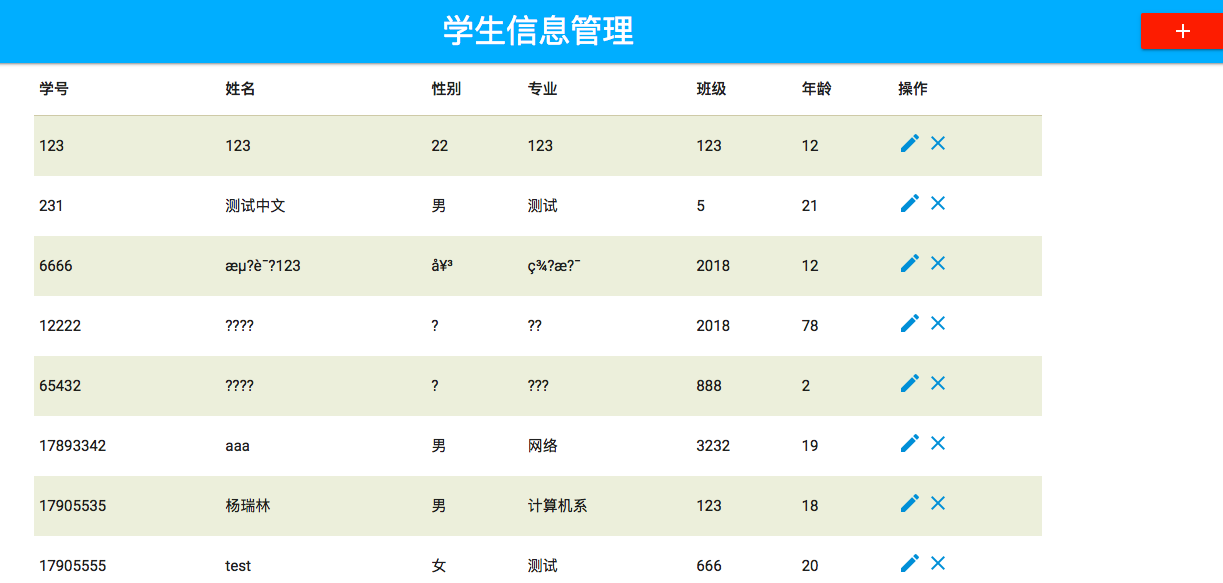
在做相关插桩的研究的过程中发现针对jsp中编写java代码的情况,因为容器会将jsp转为servlet的java文件,所以无法有效的定位到其源jsp文件的内容。
此处以openRASP为例,因为无法有效的定位到jsp文件所在内容,所以会给开发人员寻找具体代码造成困难。

由此做了相关方面的研究,并给出对应的解决方法。
where are you
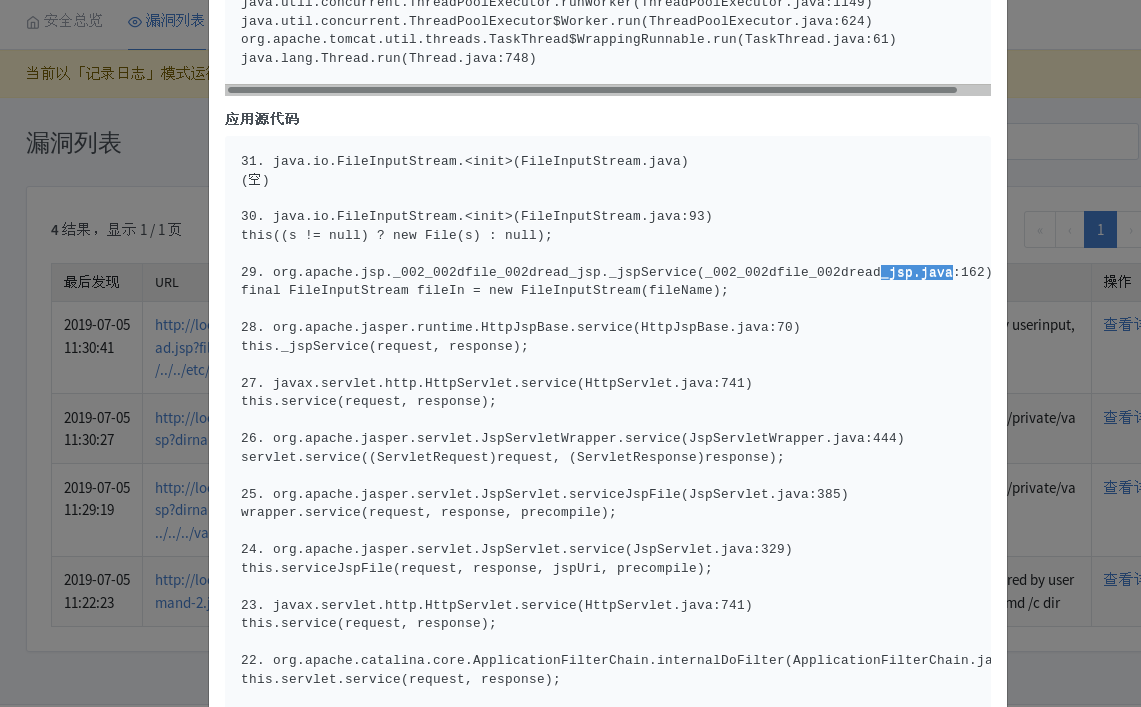
在做相关插桩的研究的过程中发现针对jsp中编写java代码的情况,因为容器会将jsp转为servlet的java文件,所以无法有效的定位到其源jsp文件的内容。
此处以openRASP为例,因为无法有效的定位到jsp文件所在内容,所以会给开发人员寻找具体代码造成困难。

由此做了相关方面的研究,并给出对应的解决方法。
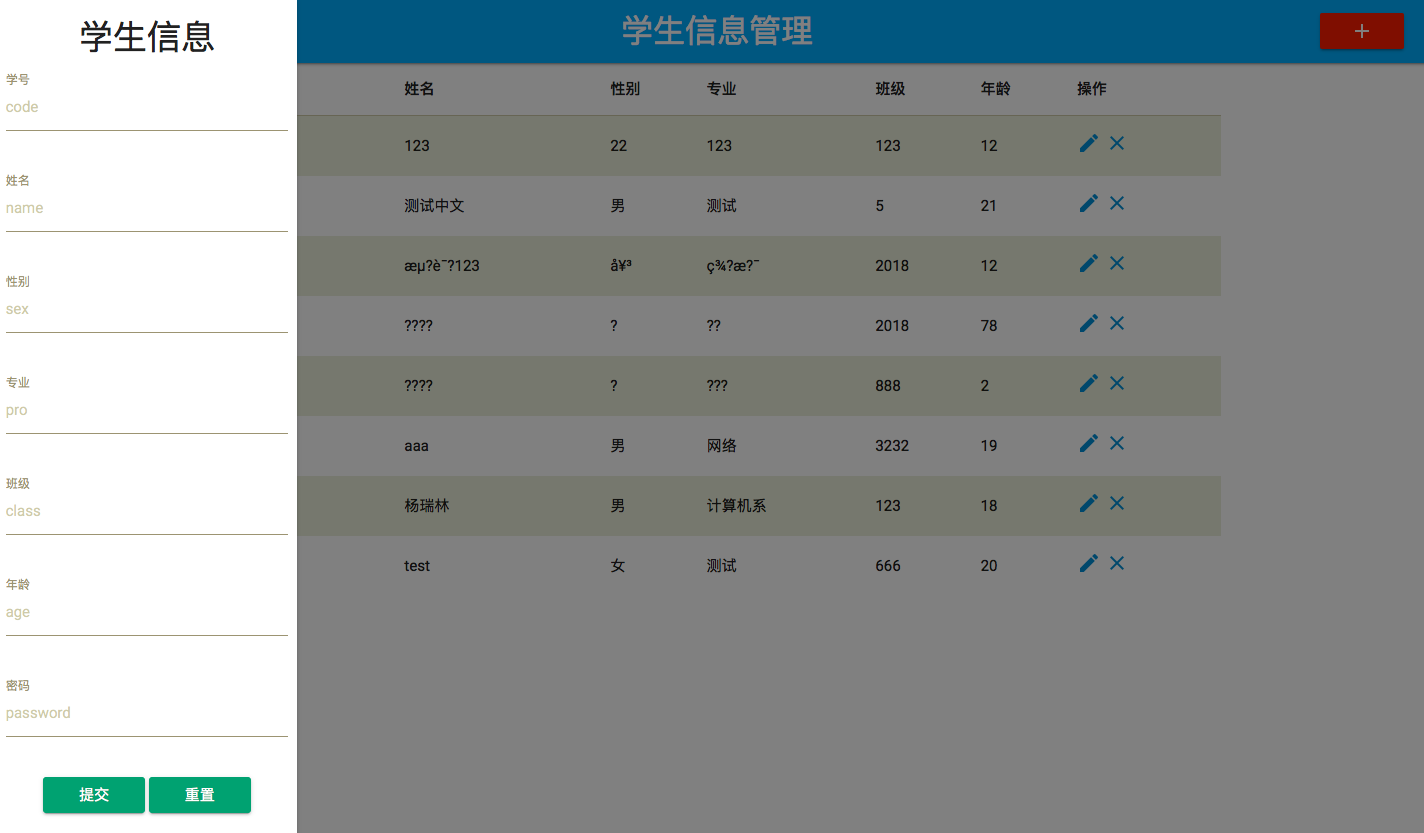
记录一下写作业遇到的问题
纠结了很久,代码是用servlet来处理form
其中post传输用户信息时一直乱码,最后查了半天才找见解决方法
- 在jsp页面的<%@ page 位置加上 contentType=”text/html; charset=utf-8″ %>,<meta 的位置也是如此:content=”text/html;charset=utf-8″ />
- 建立一个mysql数据库,字符集采用utf-8,建表也是如此。
- 在getConnection的URL中加上:?useUnicode=true&characterEncoding=UTF-8″,如:url = “jdbc:mysql://localhost:3306/(此处为数据库名称)?useUnicode=true&characterEncoding=UTF-8″,也就是在(数据库名称)的后面 //其中问号不能丢
- 如果你不是在jsp页面里直接处理form,也是和我一样采用servlet来处理form的话,那么在还要增加一个过滤器,这主要是因为采用的是tomcat的web发布器,如果用resin的话,不会有这样的问题。
package UserSystem.filter; /** * Created by Ruilin on 2017/12/19. */ import java.io.IOException; import javax.servlet.Filter; import javax.servlet.FilterChain; import javax.servlet.FilterConfig; import javax.servlet.ServletException; import javax.servlet.ServletRequest; import javax.servlet.ServletResponse; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletRequestWrapper; public class SetCharacterEncodingFilter implements Filter { class Request extends HttpServletRequestWrapper { public Request(HttpServletRequest request) { super(request); } public String toChi(String input) { try { byte[] bytes = input.getBytes("ISO8859-1"); return new String(bytes, "utf-8"); } catch (Exception ex) { } return null; } private HttpServletRequest getHttpServletRequest() { return (HttpServletRequest) super.getRequest(); } public String getParameter(String name) { return toChi(getHttpServletRequest().getParameter(name)); } public String[] getParameterValues(String name) { String values[] =getHttpServletRequest().getParameterValues(name); if (values != null) { for (int i = 0; i < values.length; i++) { values[i] = toChi(values[i]); } } return values; } } public void destroy() { } public void doFilter(ServletRequest request, ServletResponse response,FilterChain chain) throws IOException, ServletException { HttpServletRequest httpreq = (HttpServletRequest) request; if (httpreq.getMethod().equals("POST")) { request.setCharacterEncoding("utf-8"); } else { request = new Request(httpreq); } chain.doFilter(request, response); } public void init(FilterConfig filterConfig) throws ServletException { } }然后在WEB-INF目录下的web.xml文件,配置下过虑器
<filter> <filter-name>SetCharacterEncodingFilter</filter-name> <filter-class>UserSystem.filter.SetCharacterEncodingFilter</filter-class> </filter> <filter-mapping> <filter-name>SetCharacterEncodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
参考:http://blog.sina.com.cn/s/blog_6c5ad3d10100ligv.html