什么是反射
反射(Reflection)是Java程序开发语言的特征之一,它允许运行中的Java程序获取自身的信息,并且可以操作类或对象的内部属性。主要是指程序可以访问、检测和修改它本身状态或行为的一种能力,并能根据自身行为的状态和结果,调整或修改应用所描述行为的状态和相关的语义。
Oracle 官方对反射的解释是:
Reflection enables Java code to discover information about the fields, methods and constructors of loaded classes, and to use reflected fields, methods, and constructors to operate on their underlying counterparts, within security restrictions.
The API accommodates applications that need access to either the public members of a target object (based on its runtime class) or the members declared by a given class. It also allows programs to suppress default reflective access control.
简而言之,通过反射,我们可以在运行时获得程序或程序集中每一个类型的成员和成员的信息。程序中一般的对象的类型都是在编译期就确定下来的,而 Java 反射机制可以动态地创建对象并调用其属性,这样的对象的类型在编译期是未知的。所以我们可以通过反射机制直接创建对象,即使这个对象的类型在编译期是未知的。
反射的核心是 JVM 在运行时才动态加载类或调用方法/访问属性,它不需要事先(写代码的时候或编译期)知道运行对象是谁。
Java 反射主要提供以下功能:
- 在运行时判断任意一个对象所属的类;
- 在运行时构造任意一个类的对象;
- 在运行时判断任意一个类所具有的成员变量和方法(通过反射甚至可以调用private方法);
- 在运行时调用任意一个对象的方法
重点:是运行时而不是编译时
反射的主要用途
很多人都认为反射在实际的 Java 开发应用中并不广泛,其实不然。当我们在使用 IDE(如 Eclipse,IDEA)时,当我们输入一个对象或类并想调用它的属性或方法时,编译器就会自动列出它的属性或方法,这里就会用到反射,当然也有的用到了语法树。
在 Web 开发中,我们经常能够接触到各种可配置的通用框架。为了保证框架的可扩展性,它们往 往借助 Java 的反射机制,根据配置文件来加载不同的类。举例来说,Spring 框架的依赖反转 (IoC),便是依赖于反射机制。
反射invoke实现原理
invoke方法用来在运行时动态地调用某个实例的方法
它的实现代码如下:
@CallerSensitive
public Object invoke(Object obj, Object... args)
throws IllegalAccessException, IllegalArgumentException,
InvocationTargetException
{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, obj, modifiers);
}
}
MethodAccessor ma = methodAccessor; // read volatile
if (ma == null) {
ma = acquireMethodAccessor();
}
return ma.invoke(obj, args);
}
1.权限检查
通过代码我们可以看到,首先invoke方法会检查AccessibleObject的override属性的值。而AccessibleObject类是实现了AnnotatedElement,它是Field、Method和Constructor对象的基类。它提供了将反射的对象标记为在使用时取消默认Java语言访问控制检查的能力。对于公共成员、默认(打包)访问成员、受保护成员和私有成员,在分别使用 Field、Method或Constructor对象来设置或获得字段、调用方法,或者创建和初始化类的新实例的时候,会执行访问检查。
override的值默认是false,表示需要权限调用规则。我们常使用的setAccessible方法就是将其设置为true,从而忽略权限规则,调用方法时无需检查权限。
继续往下看,当其需要权限调用则走Reflection.quickCheckMemberAccess,检查方法是否为public,如果是的话跳出本步。如果不是public方法,那么用Reflection.getCallerClass()方法获取调用这个方法的Class对象
public static native Class<?> getCallerClass();
这是一个native方法,我们从openJDK源码中去找它的JNI入口(Reflection.c)
//JNIEnv: java本地方法调用的上下文,
//jclass: 在java中的Class实例
JNIEXPORT jclass JNICALL Java_sun_reflect_Reflection_getCallerClass__
(JNIEnv *env, jclass unused)
{
return JVM_GetCallerClass(env, JVM_CALLER_DEPTH);
}
具体实现在hotspot/src/share/vm/prims/jvm.cpp
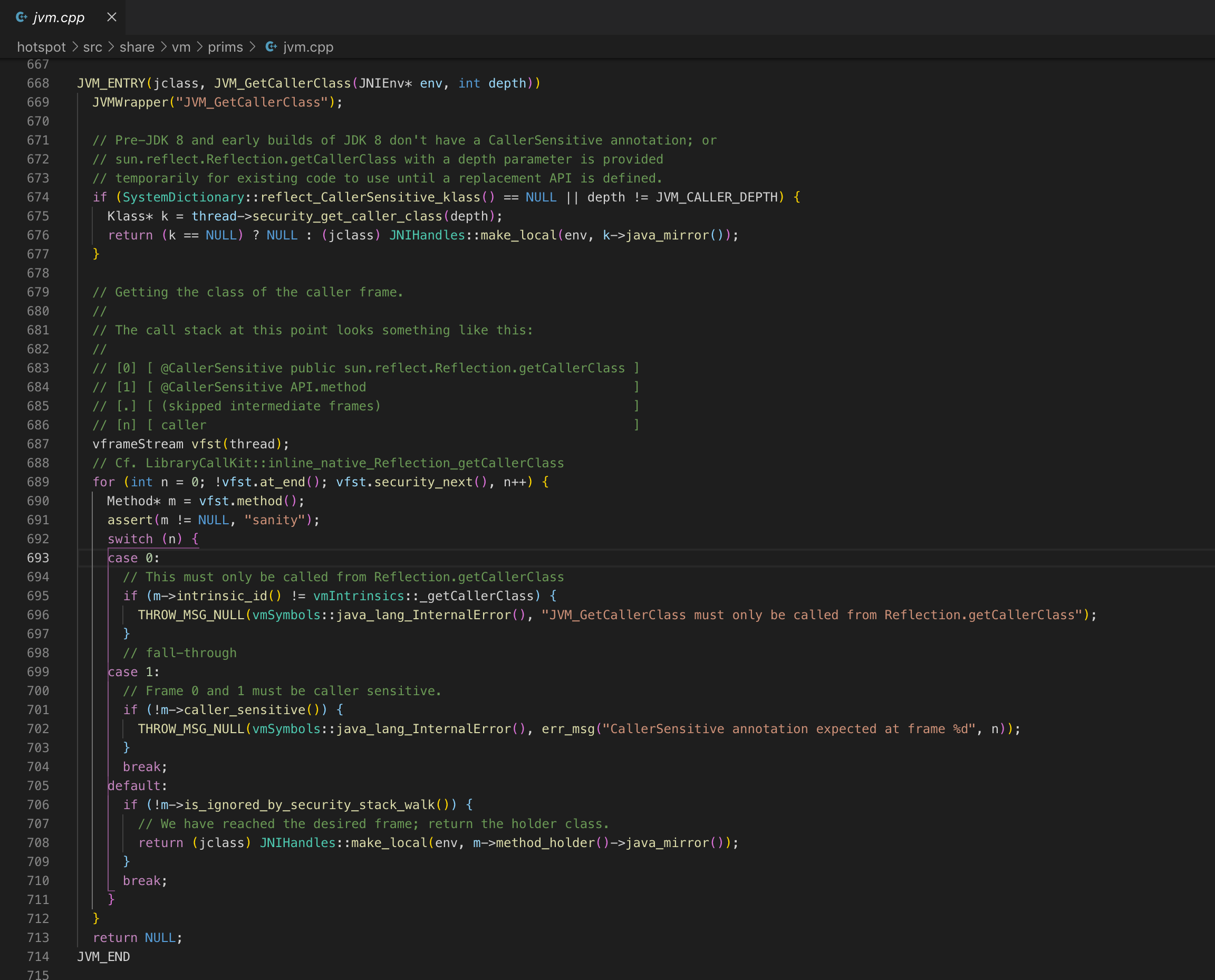 

获取了这个Class对象caller后用checkAccess方法做一次快速的权限校验
volatile Object securityCheckCache;
void checkAccess(Class<?> caller, Class<?> clazz, Object obj, int modifiers)
throws IllegalAccessException
{
if (caller == clazz) { // quick check
return; // ACCESS IS OK
}
Object cache = securityCheckCache; // read volatile
Class<?> targetClass = clazz;
if (obj != null
&& Modifier.isProtected(modifiers)
&& ((targetClass = obj.getClass()) != clazz)) {
// Must match a 2-list of { caller, targetClass }.
if (cache instanceof Class[]) {
Class<?>[] cache2 = (Class<?>[]) cache;
if (cache2[1] == targetClass &&
cache2[0] == caller) {
return; // ACCESS IS OK
}
// (Test cache[1] first since range check for [1]
// subsumes range check for [0].)
}
} else if (cache == caller) {
// Non-protected case (or obj.class == this.clazz).
return; // ACCESS IS OK
}
// If no return, fall through to the slow path.
slowCheckMemberAccess(caller, clazz, obj, modifiers, targetClass);
}
这里主要是进行一些基本的权限检查,以及使用缓存机制。
继续阅读 深入理解Java反射中的invoke方法