根据StackTrace中Java行号定位jsp行号的方法
前言
在做相关插桩的研究的过程中发现针对jsp中编写java代码的情况,因为容器会将jsp转为servlet的java文件,所以无法有效的定位到其源jsp文件的内容。
此处以openRASP为例,因为无法有效的定位到jsp文件所在内容,所以会给开发人员寻找具体代码造成困难。
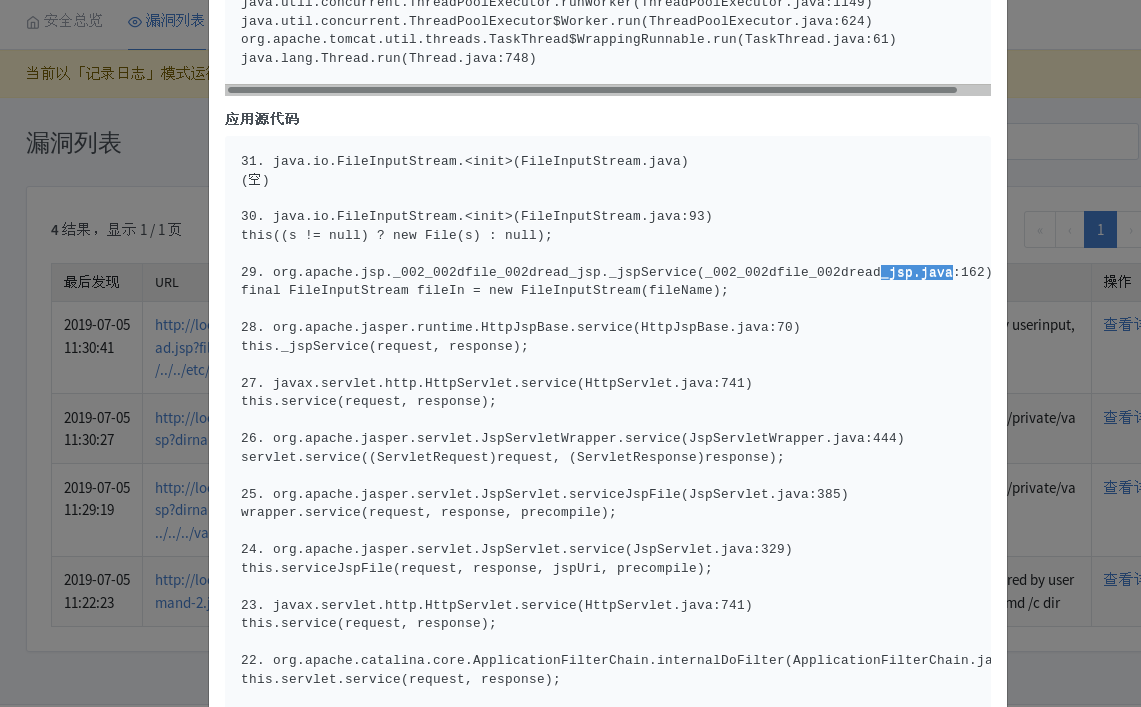 

由此做了相关方面的研究,并给出对应的解决方法。
jsp的编译顺序(Tomcat为例)
- getJspConfigPageEncoding
- determineSyntaxAndEncoding
- 解析成 Node.Nodes parsedPage 对象,即取出所有节点
- 解析每个节点
其中在第四步我们主要关注jsp中的java代码(ScriptingElement)是怎么执行的
- new一个Node节点,然后把java的字符串完整地赋值给Node的text属性,然后把node添加到Parent Node 队列(List)里面。
- 读取这些Nodes,将其转换成java源代码,然后在调用java编译器将源代码编译成class文件。(注意:这个功能相当于是把字符串,转换成了java字节码)
这个过程,调用了SmapUtil将上面那些nodes转换成Java源文件,然后调用JDTCompiler工具类,将Java源文件编译成.class文件,Tomcat调用的是org.eclipse.jdt.internal.compiler.*包下面的编译工具,实际上JDK也为我们提供了自己手动编译Java文件的方法,JDK 1.6可以用javax.tools.JavaCompiler。
两种定位方法
1.Node.Nodes
实际上在使用Tomcat跑jsp时,我们可以通过抛出一个异常来查看,它其实已经为我们定位了jsp文件的位置。
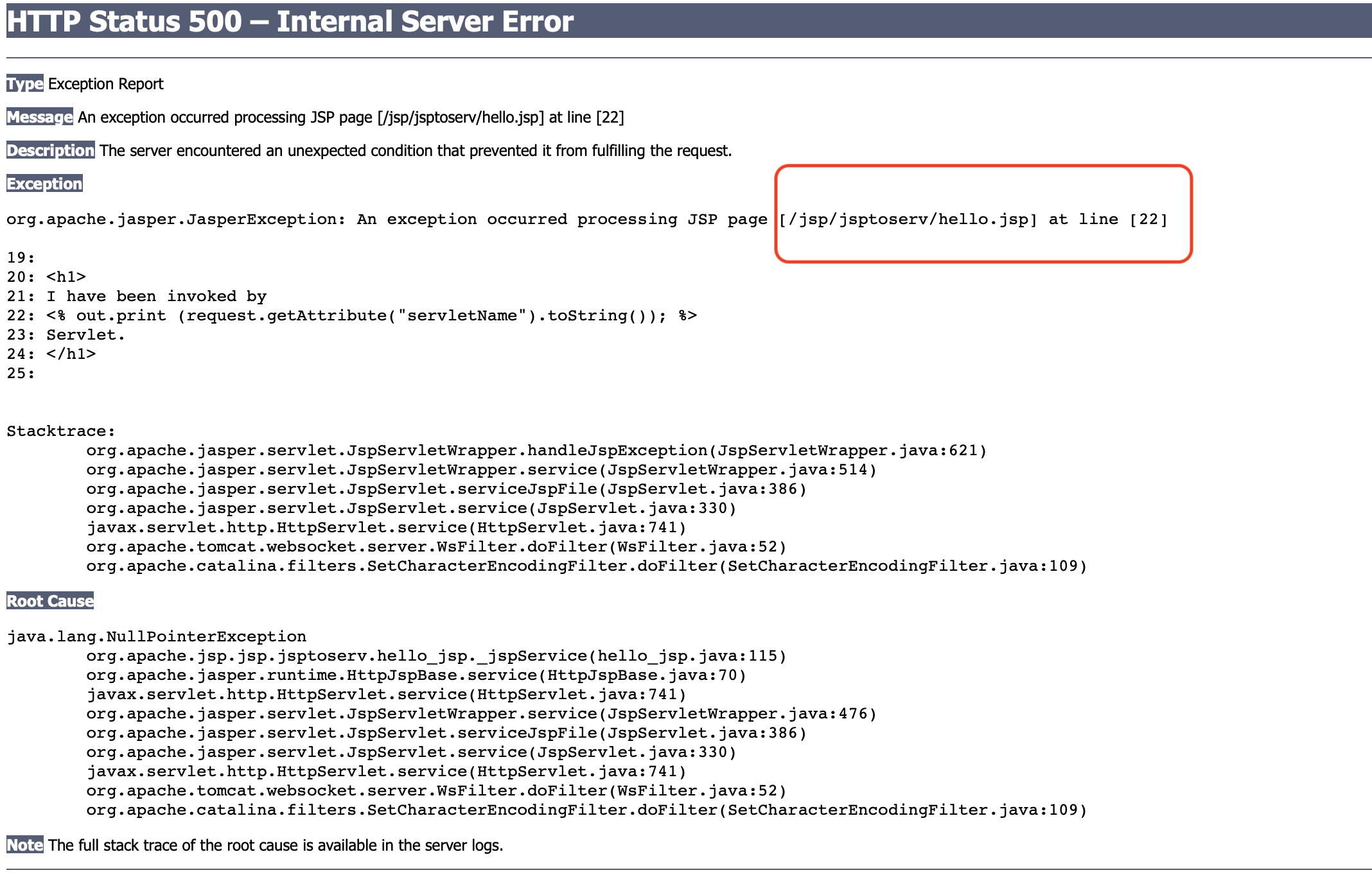 

在调试tomcat源码我们可以跟进到createJavacError这个方法
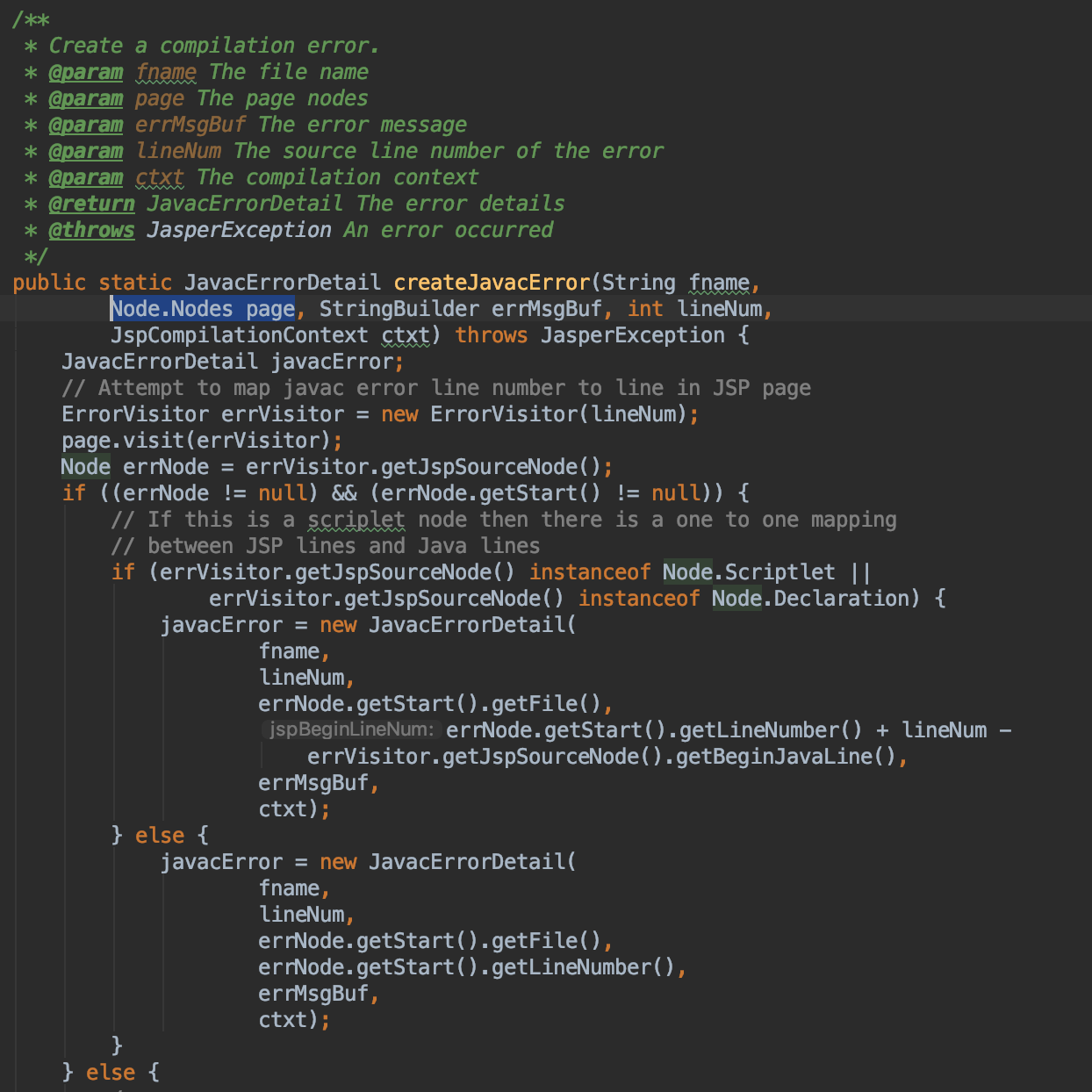 

可以看到它主要是获取了编译流程中的Node.Nodes parsedPage对象,然后获取jsp行号进行对应的操作。因为这种获取方法是在编译中进行的,所以我们没办法使用插桩的方法在编译完成后获取到对应关系,也不方便从编译开始就保存所有的node,所以此处细节不详细介绍。
2.SMAP
在一些IDE中debug时可以发现也同样为我们定位好了jsp文件
 

而它实现的原理主要是通过解析SMAP来完成的,SMAP信息默认会保存在编译后生成的class文件中,所以接下来会主要介绍SMAP的相关内容。
JSR-45规范
JSR-45(Debugging Support for Other Languages)为那些非JAVA语言写成,却需要编译成JAVA代码,运行在JVM中的程序,提供了一个进行调试的标准机制。
JSR-45是这样规定的:JSP被编译成JAVA代码时,同时生成一份JSP文件名和行号与JAVA行号之间的对应表(SMAP)。JVM在接受到调试客户端请求后,可以根据这个对应表(SMAP),从JSP的行号转换到JAVA代码的行号;JVM发出事件通知前, 也根据对应表(SMAP)进行转化,直接将JSP的文件名和行号通知调试客户端。
SMAP
根据JSR-45规范我们可以知道SMAP为jsp文件和java文件行号之间的对应表,在调试中会用于获取对应关系。
在Tomcat中对于jsp引擎的配置中有这样的两个参数
- dumpSmap JSR45 调试的 SMAP 信息是否应转储到一个文件?布尔值,默认为 false。如果 suppressSmap 为 true,则该参数值为 false。
- suppressSmap 是否禁止 JSR45 调试时生成的 SMAP 信息?true 或 false,缺省为 false。
对于其他容器,如jetty,Glassfish等一样遵守JSR-45规范,拥有关于SMAP上述两个属性配置。其中dumpSmap用于生成一个专门的SMAP文件,如XXX_jsp.class.smap。而suppressSmap默认配置为false即默认会生成SMAP信息在class文件中,我们可以通过 UltraEdit打开生成的Class文件就可以找到SourceDebugExtension属性,这个属性用来保存SMAP。
或者我们也可以直接使用
javap --verbose
来查看反编译后的附加信息
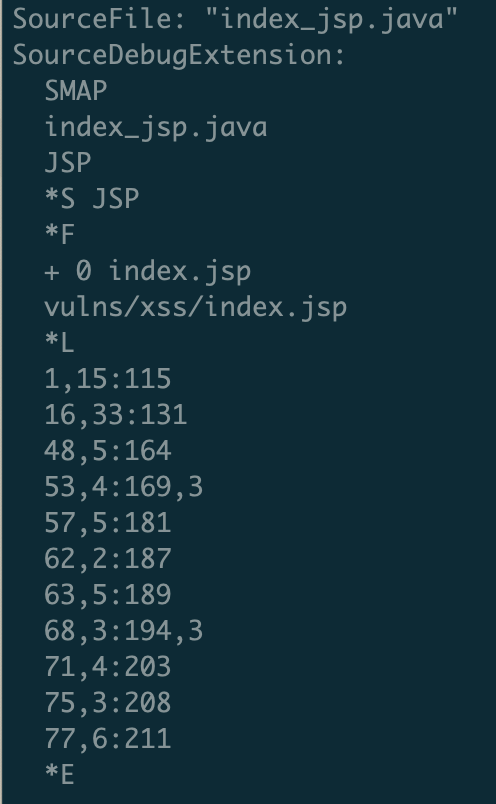 

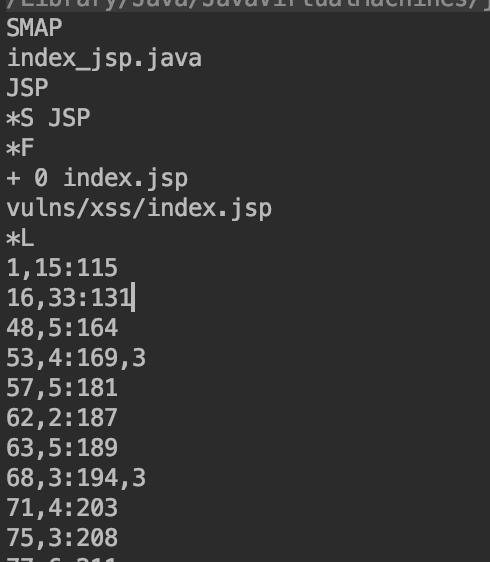
首先注明JAVA代码的名称:index_jsp.java,然后是 stratum 名称:JSP。随后是JSP文件的名称 :index.jsp。最后也是最重要的内容就是源文件文件名/行号和目标文件行号的对应关系(*L 与 *E之间的部分)
在规范定义了这样的格式:
源文件行号 # 源文件代号,重复次数 : 目标文件开始行号,目标文件行号每次增加的数量
(InputStartLine # LineFileID , RepeatCount : OutputStartLine , OutputLineIncrement)
源文件行号(InputStartLine) 目标文件开始行号(OutputStartLine) 是必须的。
 

详细的SMAP语法和映射规则等信息 可以去https://download.oracle.com/otndocs/jcp/dsol-1.0-fr-spec-oth-JSpec/ 下载JSR-45文档查看
ASM示例
ASM方式获取SMAP
1.ClassNode
public static void main(String[] args) throws Exception{
String[]files = {
"/Users/ruilin/Downloads/index_jsp.class",
};
for(int k = 0; k < files.length; k++) {
String file = files[k];
ClassReader reader = new ClassReader(new DataInputStream(new FileInputStream(file)));
ClassNode cn = new ClassNode();//创建ClassNode,读取的信息会封装到这个类里面
reader.accept(cn, 0);//开始读取
System.out.println(cn.sourceDebug);
}
}
2.visitSource
从visitSource中获取debug信息
public static void main(String[] args) throws Exception{
String[]files = {
"/Users/ruilin/Downloads/index_jsp.class",
};
for(int k = 0; k < files.length; k++) {
String file = files[k];
ClassReader reader = new ClassReader(new DataInputStream(new FileInputStream(file)));
ClassPrinter p=new ClassPrinter();
reader.accept(p, 0);//开始读取
}
}
/////////
public class ClassPrinter extends ClassVisitor {
public ClassPrinter() {
super(ASM4);
}
public void visitSource(String source, String debug) {
System.out.println(debug);
}
......
}

接下来主要就是对SMAP的解析,然后根据编译后的行号定位jsp行号。
网上已经有一些开源的对SMAP解析比较好的项目,可以使用:https://github.com/ikysil/sourcemap
我们定义一个SmapInfo用来存放jsp信息与行号,定位行号时我们用解析后的stratum与生成的java文件行号来计算出jsp行号,最终生成一个SmapInfo。
public static SmapInfo getSmapInfo(Stratum stratum, int lineNumber) {
try {
LineInfoList lineInfoList = stratum.getLineInfoList();
if (lineInfoList == null || lineInfoList.items().length == 0) {
return new SmapInfo();
}
int length = 0;
while (length < lineInfoList.items().length) {
LineInfo lineInfo = lineInfoList.items()[length];
int outputStartLine = lineInfo.getOutputStartLine();
int outputEndLine = (lineInfo.getOutputLineIncrement() * (lineInfo.getRepeatCount() - 1)) + lineInfo.getOutputStartLine();
if (length == 0 && lineNumber < outputStartLine) {
return new SmapInfo(lineInfo.getFileInfo().getInputFileName(), lineInfo.getInputStartLine());
} else if (length == lineInfoList.items().length - 1 && lineNumber > outputEndLine) {
return new SmapInfo(lineInfo.getFileInfo().getInputFileName(), (lineInfo.getInputStartLine() + lineInfo.getRepeatCount()) - 1);
} else if (lineNumber < outputStartLine) {
LineInfo lineInfo2 = lineInfoList.items()[length - 1];
return new SmapInfo(lineInfo2.getFileInfo().getInputFileName(), (lineInfo2.getInputStartLine() + lineInfo2.getRepeatCount()) - 1);
} else if (lineNumber < outputStartLine || lineNumber > outputEndLine) {
length++;
} else {
return new SmapInfo(lineInfo.getFileInfo().getInputFileName(), lineInfo.getInputStartLine() + ((lineNumber - outputStartLine) / lineInfo.getOutputLineIncrement()));
}
}
return new SmapInfo();
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
写了个demo测试获取生成java文件的187行所对应jsp行号
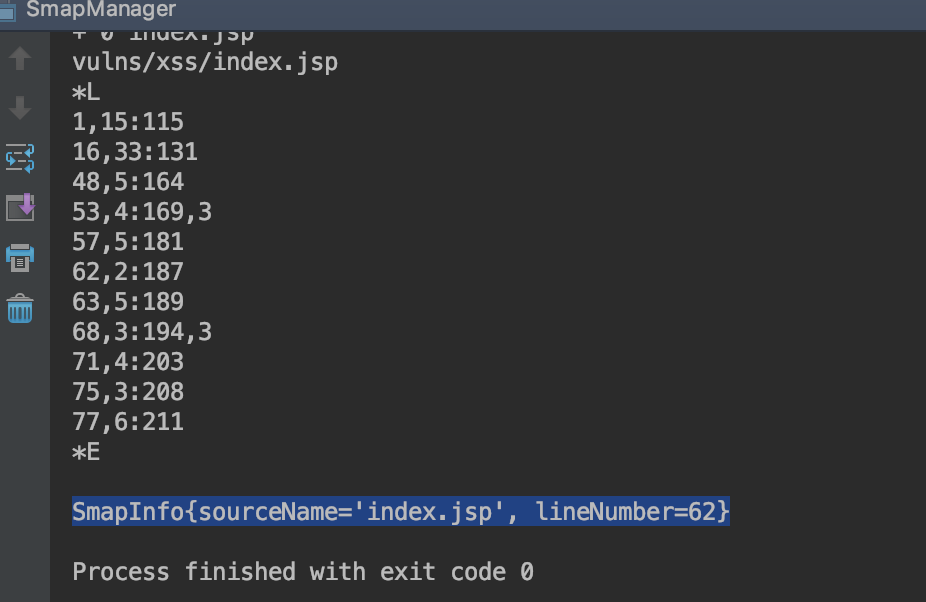 

可以看到获取正确
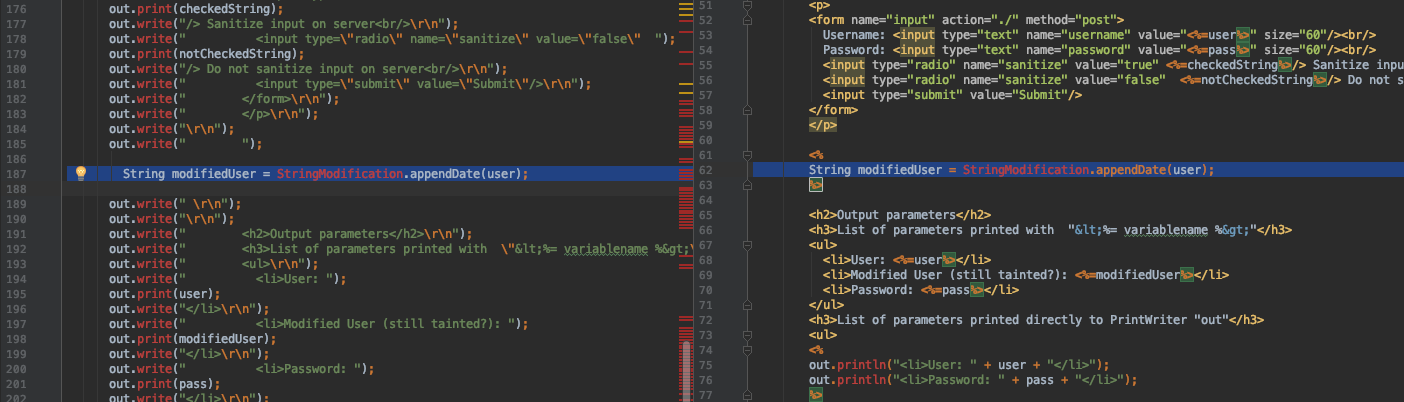 

替换StackTrace思路
通过StackTrace中java代码行号定位jsp代码行号,同时替换StackTrace的思路大致如下
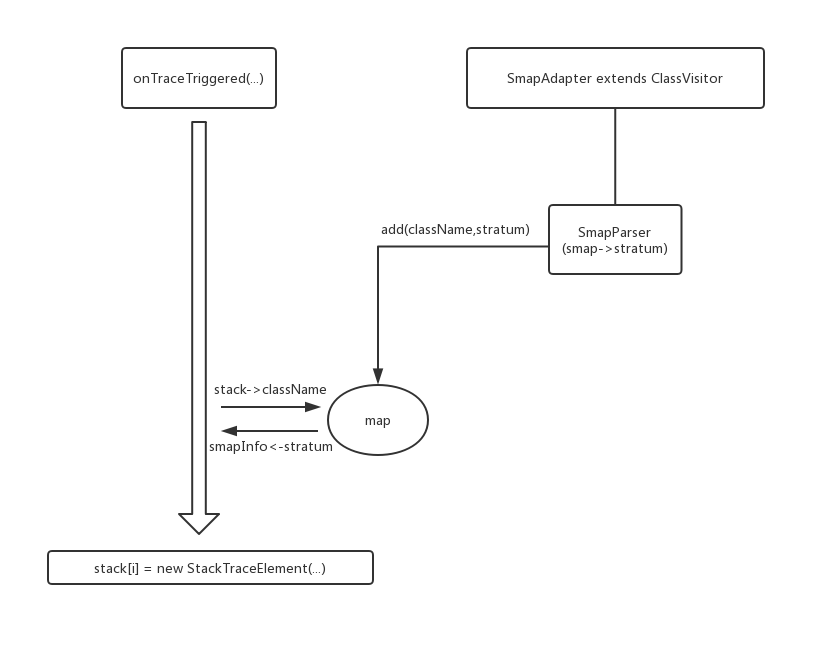 

首先jsp生成的类进入后将其SMAP信息解析为stratum并将其和className放入一个全局的map中。之后对trace的触发结束增加操作,首先判断栈里面的className是否和map中相同,如果相同则获取stratum,然后用栈中的行号与stratum中对应生成一个smapInfo(有jsp文件信息和具体行号),最后将当前栈替换为新生成的栈,其他信息不变,用smapInfo内容将文件名和行号等信息替换,即替换为jsp的文件名与行号等信息。
参考
https://blog.csdn.net/zollty/article/details/86138507
https://www.ibm.com/developerworks/cn/opensource/os-jspdebug/index.html
https://jcp.org/en/jsr/detail?id=45